topical media & game development




development(s) -- living in a virtual economy
Mashups on the Web are interesting representatives of what one may call
a
virtual economy, with a business-model that is not grounded in traditional
production and
trade values, but rather consists of value-added services
with an indirect, albeit substantial, financial spin-off, due to recommendations and referrals.
The basic mechanisms in a recommender economy are, according to
[Economy]:
recommender economy
- cross sale -- users who bought A also bought B
- up sale -- if you buy A and B together ...
Where the principles underlying this virtual economy have definitely proven their value in first (ordinary) life economy,
what are the chances that these principles are also valid, for example, in Second Life?
According to the media companies selling their services to assist the creation of presence
in Second Life,
there are plenty
New Media Opportunities In The Online World Second Life,
to a possibly even greater extent, as they boldly claim, as in what they call
the predecessor of Second Life, the World Wide Web.
To assess the role web services, including semantic web services, may play in Second Life,
it seems worthwhile to investigate to what extent web services can be deployed to
deliver more traditional media, such as digital TV.
To support the business model of digital TV, which in outline may be summarized as
providing additional information, game playing and video on demand,
with an appropriate payment scheme, [DTV] argue in favor of
the use of a SOA (Service Oriented Architecture),
to allow for a unified, well-maintainable approach in managing collections
of audio-visual objects.
Such services would include meta-data annotation, water-marking for intellectual property protection,
and search facilities for the end-user.
[Framework] even propose to wrap each individual audio-visual object in a (semantic) web service
and provide compound services based on semantic web technologies such as
OWL-S
(OWL-based Web Service Ontology)
and WSMO
(Web Service Modelling Ontology) using semi-automatic methods
together with appropriate semantic web tools,
for the description and composition of such services.
Obviously, there is a great technical challenge in creating such
self adjusting service environments.
With respect to the application of web services in Second Life, however, a far more modest aim, it
seems that nevertheless the business model associated with the delivery of media items through
digital TV channels may profitably be used in Second Life, and also the idea of wrapping media items in
web services has in some way an immediate appeal.
In [Recommend], we introduced the notion of serial recommender,
which generates guided tours in 3D digital dossier(s) based on (expert)
user tracking. See section 6.4. To incrementally refine such tours for individual users,
we used a behavioral model originally developed in [Privacy].
This model distinguishes between:
recommender model
U = user
I = item
B = behavior
R = recommendation
F = feature
and allows for characterizing observations (from which implicit ratings can be derived)
and recommendations, as follows:
- observations -- U \* I \* B
- recommendations -- U \* I
In a centralized approach the mapping U \* I \* B -> U \* I provides
recommendations from observations, either directly by applying the
U \* I -> I \* I mapping, or indirectly by the mapping
U \* I -> U \* U -> I \* I, which uses an intermediate matrix (or product space)
U \* U indicating the (preference) relation between users or user-groups.
Taken as a matrix, we may fill the entries with distance or weight values.
Otherwise, when we use product spaces, we need to provide an additional mapping
to the range of [0,1], where distance can be taken as the dual of weight,
that is d = 1 - w.
In a
decentralized approach, [Privacy] argue that it is better to
use the actual features of the items, and proceed from a mapping
I \* F -> U \* I \* R.
Updating preferences is then a matter of applying a I \* B -> I \* F mapping,
by analyzing which features are considered important.
For example, observing that a user spends a particular amount of time and gives a rating r,
we may apply this rating to all features of the item, which will indirectly influence
the rating of items with similar features.
B = [ time = 20sec, rating = r ]
F = [ artist = rembrandt, topic = portrait ]
R = [ artist(rembrandt) = r, topic(portrait) = r ]
[Privacy] observe that
B and R need not to be standardized, however F must be a common or shared
feature space to allow for the generalization of the rating of
particular items to similar items.
With reference to the CHIP project, mentioned in the previous section,
we may model a collection of artworks by (partially) enumerating their properties,
as indicated below:
A = [ p_{1}, p_2 , ... ]
where p_{k} = [ f_1 = v_1, f_2 = v_2, ... ]
with as an example
A_{nightwatch} = [ artist=rembrandt, topic=group ]
A_{guernica} = [ artist=picasso, topic=group ]
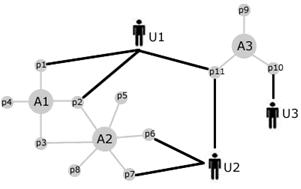
Then we can see how preferences may be shared among users, by taking into account
the (preference) value adhered to artworks or individual properties, as illustrated in the figure below.
|
|
| users, artworks and properties |
1
As a note, to avoid misunderstanding, Picasso's Guernica is not part of the collection of the Rijksmuseum,
and does as such not figure in the CHIP studies. The example is taken, however, to clarify
some properties of metrics on art collections, to be discussed in the next section.
To measure similarity, in information retrieval commonly a distance measure is used.
In mathematical terms a distance function d:X->[0,1] is distance measure if:
distance metric
d(x,y) = d(y,x)
d(x,y) <= d(x,z) + d(z,y)
d(x,x) = 0
From an abstract perspective, measuring the distance between artworks, grouped
according to some preference criterium, may give insight
in along which dimesnion the grouping is done, or in other words
what attributes have preference over others.
When we consider the artworks
a_1 = [ artist = rembrandt, topic = self-portrait ]
a_2 = [ artist = rembrandt, name = nightwatch ]
a_3 = [ artist = picasso, topic = self-portrait ]
a_4 = [ artist = picasso, name = guernica ]
we may, in an abstract fashion, deduce that
if d( a_1, a_2 ) < d( a_1, a_3 ) then r(topic) < r(artist) ,
however
if d( a_1, a_3 ) < d( a_1, a_2 ) the reverse is true, that is
then r(artist) < r(topic) .
Somehow, it seems unlikely that a_2 and a_4 will be grouped together,
since even though their topic may considered to be related, the aesthetic impact
of these works is quite different, where self portrets as a genre practiced over the
centuries indeed seem to form a 'logical' category.
Note that we may also express this as w(artist) < w(topic) if we choose
to apply weights to existing ratings, and then use the
observation that if d( a_1, a_3 ) < d( a_1, a_2 )
then w(artist) < w(topic)
to generate a guided tour
in which a_3 precedes a_2 .
For serial recommenders, that provide the user with a sequence of items
..., s_{n-1}, s_{n}, ... , and for s_{n} possibly alternatives a_1, a_2, ... ,
we may adapt the (implied) preference of the user, when the user
chooses to select alternative a_{k} instead of accepting s_{n} as provided
by the recommender, to adjust the weight of the items involved, or features thereof,
by taking into account an additional constraint on the distance measure.
Differently put, when we denote by
s_{n-1} |-> s_{n}/[ a_1, a_2, ... ]
the presentation of item s_{n} with as possible alternatives a_1, a_2, ... ,
we know that d(s_{n-1}, a_{k}) < d(s_{n-1}, s_{n} ) for some k, if the user
chooses for a_{k}
In other words, from observation B_{n} we can deduce R_{n}:
B_{n} = [ time = 20sec, forward = a_{k} ]
F_{n} = [ artist = rembrandt, topic = portrait ]
R_{n} = [ d(s_{n}, a_{k} ) < d(s_{n}, s_{n+1}) ]
leaving, at this moment, the feature vector F_{n} unaffected.
Together, the collection of recommendations, or more properly revisions R_{i} over
a sequence S, can be solved as a system of linear equations to adapt or revise
the (original) ratings.
Hence, we might be tempted to speak of the R4 framework,
rate, recommend, regret, revise.
However, we prefer to take into account the cyclic/incremental nature of
recommending, which allows us to identify revision with rating.
measures for feedback discrepancey
So far, we have not indicated how to process user feedback, given during
the presentation of a guided tour, which in the simple case merely consists
of selecting a possible alternative.
Before looking in more detail at how to process user feedback, let us consider the dimensions involved in
the rating of items, determining the eventual recommendation of these or similar items.
In outline, the dimensions involved in rating are:
dimension(s)
- positive vs negative
- individual vs community/collaborative
- feature-based vs item-based
Surprisingly, in [User] we found that negative ratings of artworks had no predictive value
for an explicit rating of (preferences for) the categories and properties of artworks.
Leaving the dimension individual vs community/collaborative aside,
since this falls outside of the scope of this paper, we
face the question of how to revise feature ratings on the basis of preferences
stated for items, which occurs (implicitly) when the user selects an alternative for
an item presented in a guided tour, from a finite collection of
alternatives.
A very straightforward way is to ask explicitly what properties influence
the decision.
More precisely, we may ask the user why a particular alternative
is selected, and let the user indicate what s/he likes about the selected alternative
and dislikes about the item presented by the recommender.
It is our expectation, which must however yet be verified, that
negative preferences do have an impact
on the explicit characterization of the (positive and negative)
preferences for general artwork categories and properties,
since presenting a guided tour, as an organized collection of items,
is in some sense more directly related to user goals (or educational targets)
than the presentation of an unorganized collection of individual items. Cf. [Hybrid].
So let's look at s_{n-1} |-> s_{n}/[ a_1, a_2, ... ] expressing
alternative selection options a_1, a_2, ... at s_{n} in sequence
S = ..., s_{n-1}, s_{n} .
We may distinguish between the following interpretations, or revisions:
interpretation(s)
- neutral interpretation -- use d(s_{n}, a_{k}) < d(s_{n}, s_{n+1} )
- positive interpretation -- increase w(feature(a_{k}))
- negative interpretation -- decrease w(feature(s_{n+1}))
How to actually deal with the revision of weights for individual features is, again,
beyond the scope of this paper.
We refer however to [OO], where we used feature vectors to find (dis)similarity between
musical fragments, and to [Features], on which our previous work was based,
where a feature grammar is introduced that characterizes an object or item as a hierarchical
structure, that may be used to access and manipulate the component-attributes of an item.
(C) Æliens
04/09/2009
You may not copy or print any of this material without explicit permission of the author or the publisher.
In case of other copyright issues, contact the author.

{kind=link}