![]()
![]()
![]()
![]()
8
virtual environments
augmented virtuality acts as an intelligent looking glass
learning objectives
After reading this chapter you should be able to characterize the notion of virtual context, discuss the issue of information retrieval in virtual environments, explain what is meant about intelligent multimedia and discuss the potential role of intelligent agents in multimedia applications.
From a user perspective, virtual environments offer the most advanced interface to multimedia information systems. Virtual environments involve the use of (high resolution) 3D graphics, intuitive interaction facilities and possibly support for multiple users.
In this chapter, we will explore the use of (desktop) virtual environments as an interface to (multimedia) information systems. We will discuss a number of prototype implementations illustrating, respectively, how paintings can be related to their context, how navigation may be seen as a suitable answer to a query, and how we can define intelligent agents that can interact with the information space. Take good notice, the use of virtual environments as an interface to information systems represents a major challenge for future research!
|
|
|
|
|
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1
virtual context
- it is a 'real world' environment
- it has 700 years of (recorded) history
- it has a fair amount of historical buildings
- buildings and street life change over time
how can we give access to the 'Dam square' information space
But now we forget one thing. The idea underlying the last scenario is that we somehow realize a seamless transition from the real life experience to the information space. Well, of course, we cannot do that. So what did we do?
|
|
{kind=link}
2
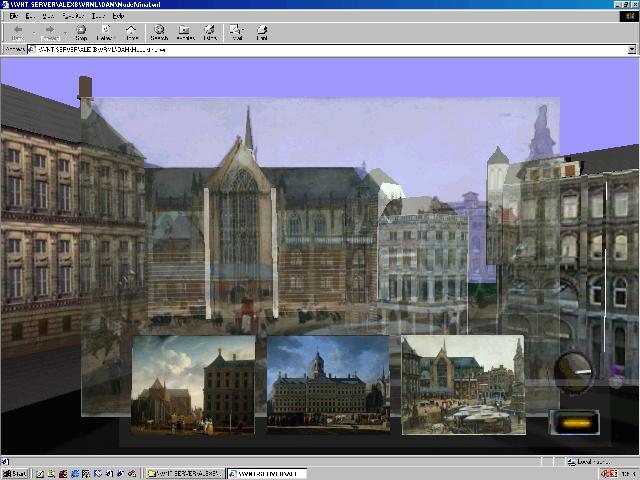
Look at the screenshot from our virtual context prototype. You can also start the VRML demo version that is online, by clicking on the screenshot. What you see is (a model of) the Dam square, more or less as it was in 2001. In the lower part, you see a panel with paintings. When you click on one of these painting, your viewpoint is changed so that you observe the real building from the point of view from which the painting was made. Then using the controls to the right of the panel, you can overlay the real building with a more or less transparent rendering of the painting. You can modify the degree of transparency by turning the dial control. You may also make the panel of paintings invisible, so that it does not disrupt your view of the Dam and the chosen overlay.virtual context
- VR model of Dam square
- selection of related paintings fromRoyalMuseum
- viewpoint adjustment, to match painting
- (transparent) overlay of paintings over buildings
augmented virtual reality
- give user sense of geographic placement of buildings
- show how multiple objects in a museum relate to eachother
- show what paintings convey about their subject, and how
problems
- organised guided tours
- account for buildings that no longer exist
- change temporal context
- allow user queries as input
VRML
VRML
- declarative means for defining geometry and appearance
- prototype abstraction mechanism
- powerful event model
- relatively strong programmatic capabilities
|
|
{kind=link}
3
research directions -- augmented virtuality
- variety of archeological sites
- various paths through individual site
- reconstruction of 'lost' elements
- 'discovery' of new material
- glossary -- general background knowledge
navigation by query
RIF
Retrieval of Information in Virtual Worlds using Feature Detectors
For the RIF project, we decided to develop a small multi-user community of our own, using the blaxxun Community Server. Then, during the development of our own virtual environment, the question came upof how to present the results of a query to the user. The concept we came up with was navigation by query, and in this section we will look at the prototype we developed to explore this concept.
|
|
|
{kind=link}
{kind=link}
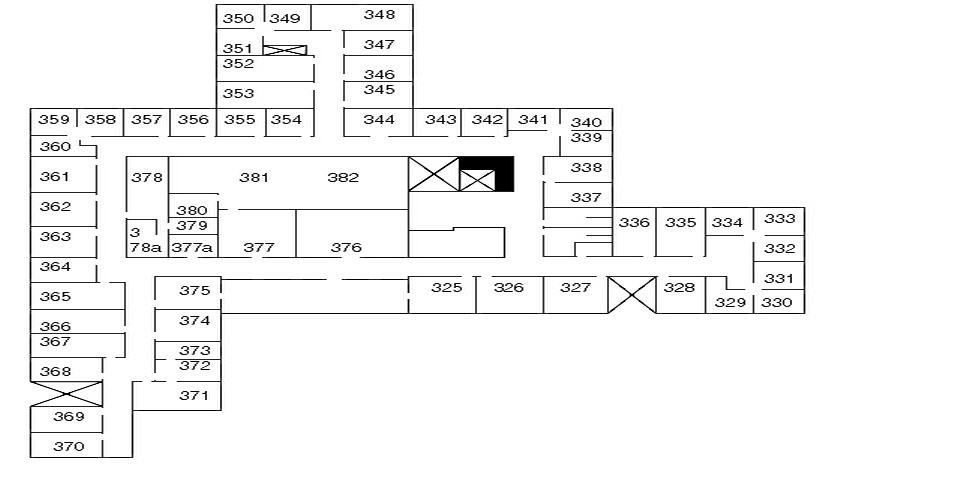
On the left is the 2D map of the third floor of CWI, on the right the model generated from it.
4
case study -- CWI
|
|
{kind=link}
5
|
|
{kind=link}
6
information in virtual worlds
types of information
- viewpoints
- areas of interest
- objects
- persons
- text
availability
- static -- always
- shared -- users
- dynamic -- runtime
- temporal -- events
- hidden -- actions
scanning the scenegraph
- annotations
- node types
- textual content
- materials
- textures
- geometry
presentation issues
choose a metaphor
get a viewpoint
- viewpoints
- areas of interest
- objects and persons
answer the query
- route planning
- viewpoint transformation
walking
the prototype
assumptions
- explicit annotation
- map for route planning
- keyword matching
requirements
- database -- annotations & map
- 3D (pseudo-immersive) interface
relaxing the assumptions
- annotation -- incremental and/or automatic
- (explicit) maps -- based on user navigation
- (keyword) matching -- text retrieval
...
- navigation by query is feasible and may help users to find locations and objects
- determining suitable navigation routes without an explicitly defined map is hard
future work
- shift in focus --
intelligent agents - DLP + VRML -- distributed logic programming
Web Agent Support Program
www.cs.vu.nl/~eliens/research
DEMO
research directions -- extended user interfaces
3D GUI
Wishful thinking about the widespread adoption of three-dimensional interfaces has not helped spawn winning applications. Success stories with three-dimensional games do not translate into broad acceptance of head-tracking immersive virtual reality. To accelerate adoption of advanced interfaces, designers must understand their appeal and performance benefits as well as honestly identify their deficits. We need to separate out the features that make 3D useful and understand how they help overcome the challenges of dis-orientation during navigation and distraction from occlusion.
Ben Shneiderman
Does spatial memory improve with 3D layouts? Is it true that 3D is more natural and easier to learn? Careful empirical studies clarify why modest aspects of 3D, such as shading for buttons and overlapping of windows are helpful, but 3D bar charts and directory structures are not. 3D sometimes pays off for medical imagery, chemical molecules, and architecture, but has yet to prove beneficial for performance measures in shopping or operating systems.
Ben Shneiderman
|
|
|
|
{kind=link}
{kind=link}
{kind=link}
7
intelligent agents
Visitors in virtual environments are often represented by so-called avatars. Wouldn't it be nice to have intelligent avatars that can show you around, and tell you more about the (virtual) world you're in.WASP
The WASP project aims at realizing intelligent services using both client-side and server-side agents, and possibly multiple agents. The technical vehicle for realizing agents is the language DLP, which stands for
DLP
Distributed Logic Programming
Merging the two projects required providing
the full VRML EAI API in DLP,
so that DLP could be used for programming the dynamic aspects
of VRML worlds.
background
RIF + WASP
- distributed logic programming -- uniform platform
- agent technology -- subsumes multi-user server
|
|
{kind=link}
8
multi-user soccer game
multi-user soccer game
- multiple (human) users -- may join during the game
- multiple agents -- to participate in the game (e.g. as goalkeeper)
- reactivity -- players (users and agents) have to react quickly
- cooperation/competition -- requires 'intelligent' communication
- dynamic behavior -- sufficiently complex 3D scenes, including the dynamic behavior of the ball
control points
- get/set -- position, rotation, viewpoint
agents in virtual environments
agents in virtual environments
- virtual environments with embedded autonomous agents
- virtual environments supported by ACL communication
Living Worlds
- scene -- geometrically bounded, continuously navigable
- world -- collection of (linked) scenes
Shared Object
- pilot -- instance that will be replicated
- drone -- instance that replicates pilot
- pilot agents -- control state of a shared object
- drone agents -- replicate the state of a shared object
- object agents -- controls a single shared object (like the soccerball) pilot at server, drone at client
- controls users' avatar pilot at user side, drone at server or clients
- autonomous agents -- like football player, with own avatar pilot at server, drone at clients
programming platform
- VRML EAI support
- distributed communication capabilities (TCP/IP)
- multiple threads of control -- for multiple shared objects
- declarative language -- for agent support
|
|
|
|
{kind=link}
{kind=link}
{kind=link}
9
PAMELA
taxonomy of agents
- 2D/3D -- to distinguish between text-based and avatar embodied agents
- client/server -- to indicate where agents reside
- single/multi -- as a measure of complexity
PAMELA
The PAMELA functional requirements included: autonomous and on-demand search capabilities, (user and system) modifiablepreferences, and multimedia presentation facilities.
- autonomous and on-demand search capabilities
- (user and system) modifiablepreferences
- multimedia presentation facilities
H-Anim
- control points -- joints, limbs and facial features
presentation agent
presentation agent
Given any collection of results, PAMELA could design some spatial layout and select suitableobject types, including for example color-based relevance cues, to present the results in a scene. PAMELA could then navigate you through the scene, indicating the possible relevance of particular results.
persuasion games
persuasion games
- single avatar persuasive argumentation
- multiple avatar dialog games
PAMELA
Persuasive Agent with Multimedia Enlightened Arguments
I agree, this sounds too flashy for my taste as well. But, what this finale is meant to express is, simply, that I see it as a challenge to create such synthetic actors using the DLP+VRML platform.
|
|
|
|
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
10
research directions -- embodied conversational agents
A variety of applications may benefit from deploying embodied conversational agents, either in the form of animated humanoid avatars or, more simply, as a 'talking head'. An interesting example is provided by Signing Avatar, a system that allows for translating arbitrary text in both spoken language and sign language for the deaf, presented by animated humanoid avatars.
Here the use of animated avatars is essential to communicate
with a particular group of users, using the sign language
for the deaf.
STEP
DLP+X3D
The DLP+X3D platform provides together with the STEP
scripting language
the computational facilities for defining semantically meaningful
behaviors and allows for a rich presentational
environment,
in particular 3D virtual environments that may include
streaming video, text and speech.
See appendix D for more details.
initial target(s) 11
The history of Second Life is extensively descibed in the official Second Life guide,
What is the secret of the success of Second Life?, we asked in
What has been characterized as a shift of culture,
from a media consumer culture to a participatory culture,
The first idea that comes to mind, naturally, is to
use Second Life to offer courses online.
But, although we did have plans to give lectures (college)
on law, probably including the enactment of a particular case,
we did consider this approach as rather naive, and frankly I see
no reason to include what may be considered an outdated
paradigm of learning in our virtual campus, where there
might be more appealing alternatives.
Similarly, using the virtual laboratory for experiments
might not be the best way to offer courses, although,
again, we do intend to provide a model of a living cell,
allowing students to study the structure, functionality and behavior
of organic cells in virtual space.
active learning 12
concepts technology
As a project, I suggest the implementation
of storytelling in virtual environments,
with (possibly) an embodied agent as the narrator.
You may further explore or evaluate
the role of agents in multimedia applications
and virtual environments.
(C) Æliens
23/08/2009
scripting behavior
Our scripting language STEP
meets these requirements.
STEP is based on dynamic logic ![]()
evaluation criteria
development(s) -- the metaverse revisited
After this first meeting, we put an announcement
on some student mailinglists, and
two and a half months later we were online,
with a virtual campus, that contains a lecture room,
a telehub from which teleports are possible to other places in the
building, billboards containing snapshots of our university's website
from which the visitors can access the actual website,
as well as a botanical garden mimicking the VU Hortus,
and even a white-walled experimentation room suggesting a 'real' scientific
laboratory.
All building and scripting were done by a group of four students,
from all faculties involved, with a weekly walkthrough
in our 'builders-meeting' to re-assess our goals and
solve technical and design issues.
(a) outside view (b) inside view
![]()
This is due to intense involvement or immersion
in the game environment, which even
encourages critical learning or as we characterized it,
following ![]()
![]()
questions
8. virtual environments
![]()
![]()
![]()
projects & further reading
![]()
the artwork
Another sequence of dutch light, opening this chapter,
is meant to make you wonder about realism.
Is virtual reality less 'real'?
With a reference to section 2.3,
where I quoted ![]()
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}