 |



Chris Verhoef
Programming Research Group
University of Amsterdam
Kruislaan 403
1098 SJ Amsterdam
The Netherlands
Phone: +31-20-525-7581
Fax: +31-20-525-7490
Email: x@wins.uva.nl
In this paper we argue that there is a necessity for automating modifications to legacy assets. We propose a five layered process for the introduction and employment of tool support that enables automated modification to entire legacy systems. Furthermore, we elaborately discuss each layer on a conceptual level, and we make appropriate references to sources where technical contributions supporting that particular layer can be found. We sketch the perspective that more and more people working in the software engineering area will be contributing to working on existing systems and/or tools to support such work.
Categories and Subject Description:
D.2.6 [Software Engineering]: Programming Environments--Interactive;
D.2.7 [Software Engineering]: Distribution and Maintenance--Restructuring;
D.3.4. [Processors]: Parsing.
Additional Key Words and Phrases:
Reengineering, System renovation, Software renovation factories,
Legacy systems, Legacy assets.
In the software IT industry, most development is about enhancing existing systems, for instance, providing new front-ends to established back-ends, capitalizing on existing relational technology for data storage, and building new interfaces to existing software assets. Organizations are more and more trying to find effective ways to reuse their investments in existing packages, data bases, and legacy assets. Componentization plays a crucial role in the opening up of reusing packages and data base technology [Allen and Frost 1998]. Realistic component-based development software engineering approaches recognize the importance of the rich body of existing software and try to bring the installed base of software in the process as an asset rather than ignoring it as a liability. One of the first books on component-based software processes was written by various authors from the Software Engineering Institute [Brown 1996]. Maybe half of the content of that book is devoted to architectural analysis, recovery, and program understanding. Also the excellent textbook [Allen and Frost 1998] on component-based development contains an entire chapter that addresses legacy systems. In such textbooks the assumption is made that technology is available to unlock legacy assets to enable reuse within the component-based software development process. Indeed software renovation plays an important role in the unlocking of legacy assets. It is the key to enable changes to software, which is often a necessity to keep in pace with the rapidly changing business goals of companies that own large information systems. Software renovation is the area where from existing systems new systems are created rather than starting from scratch. A good introduction to software renovation terminology is [Chikofsky and Cross 1990]. An annotated bibliography on the subject can be found in [Brand etal. 1997b]. The latest issues in reverse engineering, maintenance, and program comprehension can be found in the following conference proceedings [Blaha etal. 1998,Tilley and Visaggio 1998,Bennett and Khoshgoftaar 1998,Nesi and Verhoef 1999].
The reality of every-day software is that the installed base is much more brittle than we could even dream of. Aging legacy information systems are very likely to be poorly structured, and are being fixed under severe schedule pressure often by inexperienced personnel. Such systems tend to have a high bad fix injection rate. No-one dares to touch such software anymore, and when this does happen, it takes a lot of time to make the modifications. Let's take a brief look at the current situation in the IT industry. Existing software is expensive. The situation in the United States provides us with some insight: on the average, the software maintenance budget of U.S. enterprises equals or exceeds 45 percent of the total budget [Jones 1994]. We say that a software production library where the costs and resources for maintenance and enhancement are greater than for new development has high maintenance costs. More than 60 percent of Fortune 500 U.S. enterprises have high maintenance costs [Jones 1994, p. 146]. The costs of maintenance and renovation are still increasing. The expectation is that maintenance and enhancement will become the primary work of the software industry since virtually every organization will be or is computerized. Therefore, it is not a surprise that the number of people working on maintenance and enhancement of existing systems outnumber people working on development of brand-new software systems. In the current decade four out of seven software engineers are working on repair and enhancement of existing software, and the forecasts are that this trend will continue. Due to the Euro conversion work and the Year 2000 repair efforts it is estimated that in 1999 about 80 percent of the software professionals will be engaged in various maintenance and enhancement activities [Jones 1998a, p. 595].
The most common specialism in IT industry is maintenance and/or enhancement specialist. About 25 percent of software engineers are specialist in maintenance and enhancement [Jones 1996, p. 223]. If we focus on the information systems world, this percentage is even higher. About 16% of the specialists is expert in the enhancement to legacy systems, 9% is maintenance specialist for defect repairs, about 5% is specialist in geriatric care of legacy assets. This totals about 30% of the specialists who are dealing with aging legacy systems. Compare this to 1% of the specialists working on rapid application development in the IS community [Jones 1996, p. 236-7]. These numbers should not be surprising, after all, the information systems community was one of the first industries to apply computer technology to their business operations, so this industry has large portfolios of aging legacy assets.
Development of, say a car, is difficult, whereas maintenance of such hardware is less a problem. In the software world the situation is different. Maintenance and enhancement are difficult issues. Gallagher and Lyle [Gallagher and Lyle 1991] postulate
While some may view software maintenance as a less intellectually demanding activity than development, the central premise [...] is that software maintenance is more demanding.
Another indication of the difficulties that come into play with software renovation is the following metaphor: software renovation is about as easy as reconstructing a pig from a sausage [Eastwood 1992]. In [Adams 1996, p. 73] we read that a good example for which you can confidently predict failure is any large-scale reengineering effort.
Cost estimation of software activities is a crucial aspect in the information systems community. Already in the seventies the foundations for the function point techniques were introduced by Albrecht [Albrecht 1979]. Also in this area, maintenance and enhancement is the most critical aspect of software cost estimation. Moreover such cost estimation is much more difficult than estimating new software projects [Jones 1998a, p. 595].
Despite the overwhelming body of evidence that maintenance and enhancement needs more attention and is more difficult than software development from scratch, there is little focus on these topics. For instance in the software engineering research area, there is a clear need for extensive research on maintenance and enhancement topics. However, there are not many books that deal with the subject. About one out of every hundred books on software engineering discusses maintenance and enhancement as a separate topic [Jones 1998a, p. 595-6]. In fact, one of the most common 60 software risks that have been discussed in [Jones 1994] is inadequate curricula for software engineering. Courses in maintenance and enhancement of aging software is one of the recommended methods to prevent such risks.
Possible explanations of this phenomenon are of a social nature. Working on software modifications is not perceived as a challenging task. In the 1970s Danziger investigated the adoption of computers to local governments in the United States, who applied them to data-handling tasks such as accounting, issuing payrolls, and record keeping. Although the functionality of such data processing software is similar for many local governments, the so-called Not Invented Here syndrome was omnipresent. Computer programmers working for a local government thought it was more fun to re-invent a software program than simply to reuse it from another local government or to purchase it. The latter options were seen as unstimulating drudgery. Also the relatively small differences between the software that was developed in the twelve cities that were subject to this research effort were stressed as unique features, and major improvements [Danziger 1977]. This situation is still common.
Another important issue with respect to maintenance and enhancement is that it is preventive. Prevention of deterioration of software has an impact that is difficult to measure. The nature of preventive measures is to lower the probability that some future unwanted event will occur. The unwanted future event might not happen anyway, even without adoption of the measure, and so the benefits of adoption are not clear-cut. Also the prevented events, by definition, do not occur, and so they cannot be observed or counted [Rogers 1995, p. 70]. That is why contraceptives are one of the most difficult types of innovations to diffuse [Rogers 1973]. An interesting phenomenon accompanying preventive issues is known as the KAP-gap. This is the relative long time between Knowledge and positive Attitude towards a preventive measure and its actual use in Practice [Rogers 1995, p. 71]. This phenomenon is also known in the software arena: the awareness about the Year 2000 problem is rather high at the moment. Also a positive attitude towards the problem is measured. However, many companies have not taken any preventive action to avoid the problem. In other preventive software engineering practices the same pattern is at work. We briefly mention the important invention of software inspections by Fagan [Fagan 1976,Fagan 1986]. Software inspection is also a preventive measure: prevention of design errors to avoid high costs in correcting them in later stages. Gilb and Graham write in their textbook on software inspection that not everybody will be happy with this preventive technology. They speak of ``resentment or even sabotage (we'll make sure it doesn't work here)'' [Gilb and Graham 1993]. This technology also diffuses very slowly. To give an indication, Jones who has probably the largest knowledge base in the world (7000+ projects from 600+ clients), has 75 clients using formal inspections and 200 clients use some sort of more informal review process [Jones 1997, p. 215]. So despite the fact that 25 years of continuous data is available, about 30% of Jones' clients use inspections. We believe that maintenance is similar to the abovementioned cases: it is difficult to measure its relative advantage. Therefore, there is not clear-cut focus on the subject.
The total amount of installed software measured in function points [Albrecht 1979] is estimated at about 7 Giga function points [Jones 1993]. For people who are not familiar with function points, this amounts to 640 billion logical COBOL statements. Other estimates confirm the magnitude of the amount of software: in 1990 the installed base of software was estimated on 120 billion lines of source code [Ulrich 1990]. Variations in the above estimates are easily clarified by variations in methods of line counting. Depending on the methods used, a variation of one to five is possible [Jones 1986, p. 15]. For us it is important to realize the magnitude, not exact figures. Such huge amounts of software cannot simply be discarded, and they need modifications on a daily basis [Sellink and Verhoef 1999a]. It is no longer possible to do all the maintenance and enhancement work by hand. First of all there is an endemic shortage for software personnel [Rubin 1997]. Second, when the amounts of software are above a certain range, making changes by hand is not recommended [Hall 1996,Jones 1998c].
To overcome such problems, a subindustry in the software engineering area is emerging. Large investments are done in so-called software renovation factories. Such initiatives are catalyzed by the pervasiveness and size of the Year 2000 problem and the Euro conversion problem. Their employment is becoming more and more necessary in the IT industry.
In the literature focussed on large scale software engineering we can find a few characterizations of software renovation factories. The Gartner Group defines a software renovation factory as follows: a software renovation factory is a set of tools operated by a vendor (who usually owns the factory). The vendor's employees operate the technology, either by setting up the factory on-site or at a central facility [Hall 1996,Jones 1998c]. Another characterization of the factory approach is given by Jones [Jones 1994, p. 608]: the software factory concept envisions software being produced like a manufactured product more or less following the assembly line technique. Software factories are a concept that originates from Japan. Most of those factories were founded in the 1970s. For an overview of Japanese software factories we encourage the reader to consult [Matsumoto 1989]. In [Fokkink and Verhoef 1999] a formal definition is given for a software renovation factory.
When software is to be processed by a software renovation factory, this implies that the factory must have detailed knowledge of the languages involved in the system that needs modification, in the same vein as a compiler needs to know all the details on the language used. Obviously, parsers are necessary to implement this. The usual way to construct parsers is to use parser generation technology [Aho et al. 1986]. That is, the grammar of the language is expressed in some formal way and from that a parser generator tool constructs a program that indeed parses the source text and turns it into a tree for further processing. It can easily be imagined that many more language-based components play an important role in the employment of software renovation factories. For instance, when the code has been renovated, it needs to be turned into source text again, using a formatter, also known as an unparser. We can use the same grammar description that generated a parser, to generate an unparser [Brand and Visser 1996]. In fact, it is possible to generate almost all generic functionality for software renovation factories from grammar descriptions. Therefore, the grammar of the code that needs renovation is one of the most valuable assets to enable automated renovation practice.
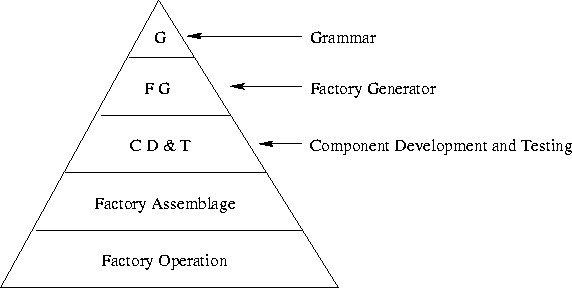
We proceed to discuss the so-called Factory Pyramid (see Figure 1). This is a five-layered view of the kind of activity necessary for the creation, development, and operation of software renovation factories. It is a pyramid to express that the lower we get in the hierarchy the more people can be employed. The top of the pyramid is labeled with a G , short for Grammar . In that layer, language engineers are employed who construct grammars for the myriad of languages involved with renovation plus their dialects. In Section 3 we will more elaborately discuss the technology they use. The profile of such people is that they are professional software engineers with a background in compiler construction and knowledge of formal language theory. The output of the language engineers consists of grammars. The second layer is abbreviated F G , which stands for Factory Generation . What happens here is that the grammars are used as input for parser generators, unparser generators, and other generators that we will discuss in Section 4. In this phase the core asset architecture supporting actual software renovation tasks is constructed. The people working in this layer should also be knowledgeable in compiler construction and the like. Moreover, they must be able to interpret the grammars and discuss them with the language engineers. The third layer of the pyramid is the part where Component Development and Testing (abbreviated C D & T ) occurs. In this layer, the core asset architecture is used to develop components that can carry out certain renovation tasks. In Section 5 we will discuss a string of examples of components that are useful for renovation. In fact, at this level a product-line for the rapid development of renovation components has been established. The people working in this layer should have a thorough knowledge of the problem domain so that they can develop the necessary renovation components fairly easy. They can be former senior developers employed at organizations that normally produce the code that is now under renovation. Then we enter the layer where assembly lines need to be integrated and where entire software renovation factories are assembled. In Section 6 we discuss examples of such assembly processes. The components that have been prototyped and tested should now be implemented efficiently, moreover their coordination has to be programmed. The latter is important so that manual intervention becomes minimal. The personnel that is necessary for such tasks are systems programmers. They do not necessarily need domain knowledge of the renovation problems. In the fifth layer we operate the software renovation factory. This means, intake of code, put it at the right location, start assembly lines in the renovation factory, keep track of the progress of the modifications, suggest improvements, suggest new tools, and so on. These are typical operator tasks and they can be done by people with less formal software engineering educations as the layers one to four.
The basic picture of software renovation is the batch oriented processing of massive amounts of code as depicted in Figure 2. A system is processed in three phases. First, the code is parsed. Then the parsed code is manipulated, e.g. transformed and analyzed. Finally, an unparser translates the parsed code back to text. This rough indication of the software renovation process gives rise to a number of more specific research topics that we will briefly discuss below.
We elaborate more on the internals of the Factory Pyramid that we depicted in Figure 1. The first major issue is to obtain extensive tool support for the language engineers. They need tools for the rapid development and reengineering of grammars. This area is called Computer Aided Language Engineering (CALE), and is discussed in Section 3. For the second layer in the Factory Pyramid, also extensive generative tool support is mandatory. We discuss some of the factory generator issues in Section 4. The resulting core asset architecture is then used by component developers. We discuss a string of examples that make apparent what kind of components are important. We provide some real-world applications from the information systems area. It is also crucial that component developers have a prototyping environment at hand. We discuss issues connected to prototyping in Section 5. Finally, the prototypes must be turned into an efficient production environment: the software renovation factory is ready. We illustrate issues connected to factory assemblage in Section 6.
It will be clear that supporting technology like sophisticated parser generator technology and/or sophisticated parsing algorithms is mandatory. Technology that is established in the compiler construction community, like LEX [Lesk and Schmidt 1986] and YACC [Johnson 1975] breaks down for renovation. There are a few reasons that support our argument. First of all, the source code that is subject to renovation is normally not equal to the code that is processed by a compiler. Consider comments in the code that need to be taken into account. Another problem is the use of embedded languages that are taken care of by preprocessors before actual compilation takes place. During a renovation, comments and embedded languages cannot be removed or expanded, they should remain intact. The abovementioned issues make clear that main stream technology is not at all sufficient. For more information on the use of parser generator technology we refer to [Brand etal. 1998d].
Technology that enables obtaining grammars for languages in a cost-effective manner is also necessary. In fact, what we call computer aided language engineering is called lingware engineering in natural language processing [Koster 1991,Nederhof etal. 1992]. The relevant issue is that we try to reuse and/or retarget grammars so that their construction time is reduced significantly. Normally the grammar of a language is discussed in some formal form. We mention standards containing language descriptions, we mention manuals of proprietary languages, we mention source code of tools containing grammar information, such as pretty printers, complexity analysis tools, and compilers. Most of the times such grammars are expressed in a dialect of the Backus Naur Formalism [Backus 1960]. Using CALE tools we can extract this knowledge and we can retarget the information into a usable form for renovation.
As an example, the normal productivity that we measured for grammar construction by hand is about 300 production rules per month [Brand etal. 1997d]. Using CALE technology we generated about 3000 context-free production rules for a huge proprietary language for real time programming. The effort took half a day. For more information on this kind of work we refer to [Sellink and Verhoef 1998a,Sellink and Verhoef 1999b].
We cannot expect that domain experts are also knowledgeable on the subject of pattern languages and so on. For example: a COBOL renovation factory should be such that a domain expert, like an experienced COBOL developer is able to work in it. Since the used programming language is a substantial factor for productivity [Jones 1986], it is crucial to design the pattern language that should be used in this factory as carefully as possible. Our solution is that we generate a so-called native pattern language from the grammar of the code that has to be reengineered. An example of a native pattern is a real code fragment. So, for instance a COBOL code fragment is a native pattern. To create more general native patterns we allow the use of variables in exactly the way they are defined in the language reference manuals. So for instance, in the COBOL manuals (like the ANSI Standard [ANSI-COBOL 1985] or the IBM COBOL manual [IBM-COBOL 1997]), the use of variables like Statement1, Statement3+, and Statement5* is allowed. The interpretation of Statement1 is that it matches exactly one arbitrary COBOL statement, Statement1+ matches one or more COBOL statements, and Statement1* zero or more. Note that the convention of numbers is common in language reference manuals to explain the language. Domain experts have seen such language reference manuals, so the learning curve for a native pattern language is close to zero. Details on the generation of native pattern languages and their use can be found in [Sellink and Verhoef 1998c].
We indicated in Figure 2 what the basic contents of a software renovation factory comprises. In this section we discussed a number of components that together form the core asset architecture to construct such a factory. The generated parser takes care of building the abstract syntax trees. The generic transformation and analysis functionality enable rapid development of tools that perform actual renovation tasks. The generated native pattern language plus its documentation helps in specifying these tools. When transformations or analyses become complex, the generated scaffolding aids are indispensable for storing intermediate results. We discuss the ensueing architecture in more detail in [Sellink and Verhoef 1999a].
Another typical task is a request for restructuring a system containing certain hard-wired coded error handling processes after an SQL statement has approached a DB2-table. An update of the IBM product DB2 provided new return codes that had to be taken into account. Therefore, the return codes had to be removed and stored in a separate program that has to be called. Another example is that over time, the structure of the error handling procedures themselves, has been modified. As a consequence, the control-flow deteriorated. With a mass maintenance transformation the control-flow could easily be updated so that the bad decision structures became natural again. For more information on such mass maintenance tasks we refer to [Sellink and Verhoef 1999a].
There are many more component development projects that one can think of. We will not mention them here, since the goal of the listing was not to be exhaustive, but to provide insight in the type of tasks that can be accomplished completely automated.
The components need to be made efficient. Sometimes this means that a developed prototype needs to be reimplemented using some scripting language like perl [Wall and Schwartz 1991]. We advise to do this only when the component is very simple, and a lexical approach does not harm at all. In our case the developed components can be compiled directly to efficient C code [Kernighan and Ritchie 1978]. Important supporting technology is the use of an expert compiler that turns our formally specified components into efficient stand-alone C programs [Brand etal. 1998b]. This is all necessary since issues like scalability, multi-processor calculations and such play an important role when millions of lines of code have to be processed. The factory assembler also takes care of the coordination of the renovation components. Sometimes this implies a separate program that takes care of the coordination, like a perl script or a C program. In other cases, we use middleware to connect the components. Important supporting technology for such coordination is middleware that is geared towards the connection of language oriented tools, called the ToolBus [Bergstra and Klint 1996b,Bergstra and Klint 1996a,Bergstra and Klint 1998]. The expert compiler generates C code that can be directly connected to the ToolBus so that it is not necessary to change the code in order to connect it to middleware. However, if there is no need to use middleware, the code can also run without the ToolBus.
Another task of the factory assemblage team is to take care of the releases of the factory with all its assembly lines. To give the reader an idea, in one case a Y2K factory of a reengineering company has a weekly release. Then a lot of test-runs have to be performed, version management, and so on all come into play.
To give the reader an idea of the state-of-the-art with respect to rapid delivery of efficient renovation factories, we mention that we have a COBOL renovation factory architecture for which prototyped components can readily be compiled and used in a production factory. The factory can deal with many COBOL dialects, with embedded CICS and/or SQL. There is sophisticated pre- and postprocessing of the code. This includes issues like temporary expansion of so-called copy books--comparable to an include file in C. In [Brunekreef and Diertens 1999] a production environment has been developed after a set of components had been prototyped for a specific project. In this case the project was a feasibility study for a large bank to see whether it was possible to convert a modern COBOL dialect (from 1985) back to an older dialect (a COBOL dialect from 1974). Note that the backward transformation is not a typographical error. There was a very good reason for converting the code back to an older dialect, see [Brunekreef and Diertens 1999] for details. To give the reader an idea of the work that is necessary during the factory assembly stage, it took not more than an hour to compile efficient components from the prototypes and since their coordination was a pipeline, there was no effort in the coordination. So in about half a day, we could to move from the third layer to the fourth layer. In general, when there is no executable prototype, or no automatic means to compile the prototype into efficient code, the factory assembly phase boils down to a classical software development project. In this case the actual implementation will presumably take more than half a day.
The real-world case study [Brunekreef and Diertens 1999] also indicates that academics cannot invent their own reengineering case studies: they have to come from IT industry. For more information on the use and construction of software renovation factories we refer to the papers [Brand etal. 1996,Klint and Verhoef 1998,Brand etal. 1998a]. For academic readers interested in the difficulties and problems to overcome when dealing with IT industry, we refer to [Brand etal. 1998a].
It is also known that programmers working on a system for some time, typically maintenance programmers, consider the code to be their own [Weinberg 1971]. Therefore, it is not so easy to outsource maintenance. If this happens, there is a serious danger that the maintenance team will reject the code that is returned to them. For, they are deprived of their code, indicating that they do not do a proper job. Then strangers touch it, and they break it. Sneed mentioned (in a keynote address to the fourth Working Conference on Reverse Engineering [Baxter etal. 1997]) that he experienced this phenomenon in an off-shore outsourced Year 2000 conversion [Sneed. 1997]. Such hostile attitudes towards maintenance outsourcing should be taken into account when dealing with automated tools. Therefore, our approach is to bring factories to the maintenance teams so that they can operate them.
One of the reasons that there is a lack of advanced aids for maintenance and enhancements, is that people are naturally learners. Therefore, the competence of a maintenance team to maintain a particular systems grows over time, possibly masking the deterioration of the system [Weinberg 1992, p. 243]. Their competence also hides the fact that many tools are necessary. Over time a lot of knowledge is being put in the heads of the teams. If this knowledge is put in automated tools, a lot of such specific knowledge is put inside the tools. If that happens, a sudden exodus of the maintenance crew is less disruptive for the maintenance assignment scope of novices than usual. Therefore, intensive communication between the maintenance team and renovation component developers is necessary.
The intensive communication turns the usual fear of the factory--also known as mechanophobia--with its regularity, order, control and discipline into a blessing that frees the maintenance teams to perform error-prone and repetitive tasks, because the factory will do the repetitive work. In the mean time they can order the tools necessary while communicating with the factory team. This is not only a hope for the future, but this is actually happening. We learned from two major reengineering companies who employ many Y2K factories on four continents, that the people working in these factories feel empowered by the flexibility of the approach taken in the factories. The problem reports and change requests have lead to a weekly release of their Y2K factory. This intensive interaction between factory workers and factory constructors makes that the maintenance programmers like their work instead of showing luddite traces in their behavior.
One way to encourage a factory approach towards modifications of software portfolios is to educate enhancement programmers, with tools, training, and resources. Also maintenance teams should be paid better. However, compensation plans for maintenance programmers is out of scope for this paper. We stress that these issues, as well as encouraging people to participate in education is a managerial responsibility. We encourage managers to take note of the book [Weinberg 1971] for learning more about the psychology of computer programming, and the book [Weinberg 1988] for understanding more of the professional programmer.
Summarizing, migrating handwork of maintenance programmers to a factory approach gives them the unique opportunity to discuss their problems with others, the factory constructors. They in turn construct assembly lines that unleash the knowledge that would normally not be outside the heads of the maintenance crew. This is a corporate asset. Both the interaction and tools give the factory operators the (correct) feeling that their work is important, difficult and appreciated. Management should support such changes in the organization. Help with managing the introduction of automated tools in an organization can be found in books like [Pressman 1988,Bouldin 1989].
Software renovation is using tomorrow's technology to bring yesterday's software to the level of today.
