|
Alex Sellink*,
Harry Sneed**,
Chris Verhoef***
*Quack.com, 1252 Borregas Ave, Sunnyvale, CA 94089, USA
**SES Software-Engineering Service GmbH, Germany
***University of Amsterdam,
Programming Research Group
Kruislaan 403, 1098 SJ Amsterdam, The Netherlands
slinky@quack.com, Harry.Sneed@t-online.de, x@wins.uva.nl
Categories and Subject Description:
D.2.6 [Software Engineering]: Programming Environments--Interactive;
D.2.7 [Software Engineering]: Distribution and
Maintenance--Restructuring;
Additional Key Words and Phrases: Reengineering, System renovation, COBOL, CICS, Teleprocessing system, Transaction processing system, Control-flow normalization, Repartitioning, Remodularization.
Many organizations have interactive business-critical applications in use for which it is important that they can be enhanced considerably. Change is not the exception for these systems, it is the norm [37]. Typical changes are migration to client/server, accessibility via Intranet/Internet, changed business needs, improving maintainability, to mention a few. In order to give an idea of the significance of this area: the majority of the code maintained in the world is a part of a transaction system and this trend will continue. Keeping such systems in good shape and allowing them to evolve is extremely important for developed society [37]. Many such applications have been implemented using COBOL, PL/1, or Assembly/370 for the batch part and CICS (Customer Information Control System) for the interactive part. In [10] it was pointed out that in order to reengineer such systems, certain problematic CICS constructs should be removed. In that paper a strategy was mentioned in order to automatically remove them in favor of other constructions so that the above typical enhancements can be made. Sneed implemented some of these ideas in his reengineering workbench [56]. In this paper we continue the treatment of restructuring COBOL/CICS systems.
In general, it is cost-effective to restructure applications. The return on investment of every dollar spend to restructuring tools is good: $2.50 after one year, $5.00 after two years, $6.00 after three, and $8.00 after four years [31]. The findings of Jones are confirmed by several studies. We epitomize on some of them, since the subject is of utter importance for the area of reengineering (but quantitative data is unknown by many).
Restructuring of legacy code eases maintenance significantly. In a 1987 study on COBOL, sponsored by the Federal Software Management Support Center of the U.S. General Services Administration [18] we can read:
the report provides convincing evidence to support the contention that restructured programs are less expensive to maintain than are unrestructured programs. It clearly indicates that the amount of time associated with the analysis and test of maintenance changes can be reduced significantly through prudent implementation of a restructuring strategy using tools and appropriate support methodologies designed for that purpose.
The following (expensive) experiment was carried out: for a set of programs two versions were created upon which the same maintenance tasks were performed by two separate teams. One team used the original programs and the other team used the restructured programs. The programs were automatically restructured using a tool called Recoder developed by Language Technology of Salem, Massachusetts. The product is now called VISION:Recode, and sold by Sterling Software. The recoded versions demonstrated a 44 percent reduction in maintenance and test time [18]. On the negative side there were severe parsing problems and the implemented algorithms were not always giving output that satisfied the involved programmers: style, structure, and names of identifiers were criticized. Maybe these problems were due to the algorithms that were used during the restructuring. We stress that in spite of these negative reactions, the productivity improved significantly. In our setting it is possible to use an interactive approach in which the reengineer guides the restructuring. Once there is a satisfactory interactive solution, it is possible to automate it.
For people who do not have access to [18], there is a two page summary of the 61 page report in ComputerWorld [3]. In 1991, Language Technology Inc. carried out another experiment confirming the above numbers: the effort for making the same change was 40 percent less when the change was made to a well-structured base system (cyclomatic complexity <5) as when made to the same system in a poorly structured (cyclomatic complexity >20) form [29]. A series of 26 interviews by Capers Jones in the seventies with IBM systems programmers in California (13 were fixing bugs; 13 were adding enhancements) reached a similar conclusion: working with well-structured base code was between one fourth to twice as fast as with poorly structured for any given update. Also the bad fix rate was asserted to be lower than 50 percent [29], a clear sign of improved maintainability. For, the bad fix rate for even one-line maintenance changes can be considerably high: in [19] a research at a software maintenance organization pointed out that 55 percent of one-line changes were in error before code reviews were introduced. Another example that confirms the results of the 1987 study [18] is reported on in [37]. In one project the time required for a new maintainer to learn the code had dropped from about 18 months prior to restructuring to approximately 6 months afterwards. On this system the maintenance staff before restructuring consisted of three senior maintainers and three junior maintainers. After restructuring the system is maintained by three to four junior maintainers [37]. The authors of [37] consider the results, although indicative, not generalizable to other organizations and systems, since they looked at one system. A large-scale example is below.
A good example of a company that adopted restructuring before enhancing is Hartford Insurance. They have been exploring maintenance costs for more than 15 years, and have published that their maintenance assignment scope has tripled and their annual maintenance budget is below 19 percent and dropping [29]. Compare this with the frequently heard phrase that 30 percent of the total costs of a system are devoted to its initial construction: the remaining 70 percent are spent on maintenance and adjustments to new requirements and new operating environments. These costs are confirmed in many studies [41,46,4,30,45]. McConnell [42] gives a summary of these findings. The decreases at Hartford Insurance were not caused by a decrease in the volume or amount of changes. Rather, the decreases were attributable to their program of restructuring and remodularizing their legacy systems prior to carrying out extensive updates [29]. So there is enough evidence that restructuring significantly improves maintenance and significant enhancements. One can say that major restructuring is a prerequisite to large-scale renovation.
In this paper we address the restructuring of programs written in mixed languages: COBOL interspersed with CICS commands. We note that it is far from trivial to deal with mixed languages. An indication of the problems is given by Jones: 30 percent of the U.S. software applications contain at least two languages. Jones moreover states that most Year 2000 search engines come to a halt when multiple programming languages are used [31]. So mixed languages are not uncommon and tool support is not easy to develop, since parser technology normally does not deal with mixed languages. For an elaborate discussion on how to deal with mixed languages and reengineering/reverse engineering we refer to [11]. We refer to [9] for a method to obtain a reengineering grammar by hand and we refer to [52,53,40] to obtain such grammars using extensive tool support. The tools that the authors develop can deal with mixed languages (see [11] for details).
In addition to the parsing problems, what else comes into play when restructuring COBOL/CICS systems? A major problem is the exception handling mechanism of CICS: the so-called CICS HANDLE commands. In [23] a formal specification in Z [59,60] of the HANDLE CONDITION revealed counter-intuitive behavior of this construct. Hayes (the author of [23]) mentions that the exception handling mechanism is so complex that most readers of either the manual [24] or the Z specification [23] do not discover the subtle behavior that was revealed during the formalization process. Hayes advises in 1985 revision of exception handling to be more intuitive. In 1987 Goldstein [20] also addresses the problems with the CICS HANDLE commands. CICS programs are very dependent upon the HANDLE CONDITION and HANDLE AID commands for error detection and special key use determination [20]. Goldstein advices to restrict the use to a single HANDLE ABEND to avoid unpredictable results from the program. In a reaction on Goldstein's paper, Jatich [27] states that all HANDLE commands should be eschewed entirely. Also in his comprehensive textbook on CICS command level programming [28], Jatich discourages the use of HANDLE commands, because of the unstructured logic.
Despite the many warnings reported in the literature, the use of HANDLE commands is still omnipresent in modern and legacy COBOL/CICS systems. When we wish to improve maintainability, or when we wish to migrate COBOL/CICS systems, we must remove the HANDLE commands. Note that this is in accordance with the successful Hartford Insurance strategy: their first step towards major enhancements is extensive restructuring.
In [32] CICS is characterized as being stable, mature and feature-rich. This richness turns into mean complexity when reengineering comes into play. The expressiveness of CICS does not always translate easily to new environments, leading to sleepless nights wondering how to implement replacement functionality [32]. Apparently, the problem is so intricate that [32] proposes to use a dedicated processor (the Personal/370 adapter card), in order to run mainframe applications without a change on PCs. In this way off-loading is fast and thus cost-effective [32]. On the other hand, the authors of [58] indicate that off-loading is a very difficult problem. Jones reports that the assignment scope of migration to new platform is 1800 LOC per month [30, loc. cit. p. 600], which is another indication that the problems are huge and that extensive tool support is of economic relevance. Needless to say that reengineering CICS applications is a difficult problem.
This paper deals with the intricate problem of restructuring COBOL/CICS systems. We eliminate the exception handling by CICS, the processing logic is structured, the code is repartitioned so that maintainability improves and migrations to client/server architecture become feasible.
It is highly unlikely that users will finance a restructuring project solely for the purpose of improving the internal quality of a product, i.e., its maintainability, even if case studies such as the ones we mentioned in the introduction demonstrate the long term benefits. For the typical IT shop, the benefits of improving maintainability are still too low compared to the costs and risks involved [55]. It has always been an illusion of the academic community that users are really interested in quality, whereas, as a fact, they are mainly interested in functionality and only partially in quality. Even then, quality is perceived as the quality of the external behavior of a system and not in its internal construction. For this reason, there has never been a significant market for restructuring projects and products, as such. Another reason is that any code modification bears the risk of failures. What happens if the restructured code has different semantic behavior than the original code? We note that restructuring often reveals erroneous and dangerous code, so that it is tempting to repair that. Or sometimes it is automatically repaired, due to the used restructuring algorithms. Such corrections can, in turn, trigger errors to occur that due to the original errors, laid dormant in the application. This is a risk that the owners of the systems do often not want to take only for improvement of internal quality.
Migration is another issue. Users are often compelled to move from one environment to another or, moreover, they need to reuse old programs in a new context. The latter objective has become very important in connection with component-based software development [17,1,16]. Then restructuring is accepted as a part of the migration process since the programs have to be altered anyway. However, the main objective is to get the old system to work in the new environment and not necessarily to make it better. Existing programs can be reused as components of a newly developed system provided they meet certain conditions. They must fit into the new architecture, that is, their external interface must be remotely accessible via various calling mechanisms such as remote procedure calls, object request broker connections, or Java's remote method invocations [21]. Besides that they must be made independent of their environment, i.e, made self-contained, their behavior must be predictable and they should produce no side-effects. This is where restructuring comes into play. Restructuring of legacy programs is done to
To provide remotely accessible interfaces, the existing interfaces must be modified. In the case of batch programs these are the read and write operations performed on transaction files managed by the operating system. In the case of on-line programs these are the send and receive operations performed on the maps managed by the teleprocessing monitor. The latter is particularly difficult because of the many interactions between the application program and the transaction monitor. The application program is essentially reduced to a subprogram of the transaction monitor which is reacting to events triggered by the transaction monitor. For the sake of wrapping this is a suitable solution, but the interactions have to be altered to fit the wrapper. Therefore, interface reengineering is one of the targets we deal with in this paper.
To insulate the program from its environment, all references to services provided by that environment must be redirected. In the case of CICS many services are provided by the transaction processing monitor including memory allocation, error handling and program to program linkage. If the user program is to be taken out of the CICS environment, then these service requests have to be redirected to the wrapper, i.e., converted to CALLs to user-provided or standard routines which perform the same services as provided by CICS. This entails converting all service requests, another objective of the work presented here.
To isolate functions of the program from one another, all direct interconnections between functions must be capped. That means removing all jump instructions. Functions or subroutines in COBOL are packed in paragraphs or sections. A GO TO from one paragraph to another joins the functions of those paragraphs. If programs are to be reused as components, we should be able to invoke their functions independently of one another. The paragraphs or, at least, the sections of a COBOL program should resemble methods in order to provide discrete functionality to potential clients. The program needs to be modularized, that is, partitioned into reusable parts. To achieve this, it has to be restructured. Then, the sections of the program are no longer embedded in a hard wired control structure imposed by that particular application, but are independent functions which may be invoked in any order. This gives the flexibility required in a modern component-based environment. To this end restructuring is a necessary prerequisite to wrapping.
Finally, there is the goal of eliminating side-effects. In CICS most side-effects stem from the use of a common global data area. Addressing errors can create havoc, as one program overwrites the data of another. To prevent this, one program should not be able to directly access the data of another. All data should be passed as a parameter by value. To achieve this, parameter lists must be generated for all global data used by the program. The program itself becomes stateless. It has no own memory, but only processes data passed to it as a message. The capping of global data references is the last stage of the transformation process described in this paper.
In order to realize on-line transactions on the mainframe, IBM users had the choice between the teleprocessing monitors CICS [24] and IMS-DC [25]. Both teleprocessing monitors were originally developed in the late 1960s and have gone through several revisions since then. Throughout the 1970s and 1980s these two teleprocessing monitors dominated the industry. In [23] we can read that there is a large number of CICS systems around the world. Twelve years later, [37] report that the majority of code to be maintained in the world is part of a transaction system. So, many on-line applications developed on a mainframe were developed with the help of CICS.
The role of a teleprocessing monitor is essential to on-line transactions. The teleprocessing monitor is itself a complex program which fulfills all of the necessary functions required to run a user program in on-line mode. It provides most of the standard functions required by application programs for communication with remote and local terminals and subsystems. It establishes the connection to a user terminal, queues the user messages, allocates memory space, copies the next user message into the program input buffer, picks up the output messages from the program output buffer, processes file or database accesses, takes the user program in and out of a waiting state, intercepts all service requests by the programs, handles error exceptions, and establishes connections between programs. It takes care of the control for concurrently running user application programs serving many on-line users. In effect, the teleprocessing monitor is an operating system within an operating system. Only the system calls are of a higher level since they also provide security checking, logging and error recovery and such [15,28].
Besides this, teleprocessing monitors have their own interface between application programs and terminal devices. IMS-DC uses Map Format Service (MFS) and CICS offers Basic Mapping Support (BMS). The screen handling facility displays the maps which are specified with an Assembler type macro language, extracts the variable field contents, creates an input data stream from these contents, inserts the variable field contents from the output data stream and manipulates the appearance of the map based on the attributes of the fields [24]. The screen services are the old solution to customizing the user interface. Originally the user programs requested the services provided by the teleprocessing monitor by means of CALL commands. This had the advantage that inclusion of teleprocessing code did not introduce mixed languages in the source: COBOL remained COBOL, PL/1 was still PL/1, and Assembler remained Assembler, which made it compliant with all tool support available for these languages. The problem at that time was to recognize by means of the parameters used what kind of function was being invoked. In the end, this CALL interface solution turned out to be very clumsy for users to write and was a continuous source of errors since bad parameters could only be detected at run time. So IBM decided to design two domain specific languages dealing with on-line transactions, by replacing the standard CALL interfaces with macros which could be processed by a preprocessor. In Section 3.1 we will see some code plus the output of such a preprocessor. Note that the embedded code is first preprocessed and then turned into the host language, and then compiled. So in Section 3.1 we will see translations of CICS to COBOL code. We note that when reengineering such code, it is not a good idea to first preprocess embedded CICS code, and then to start reengineering: the mixed language code is the source code for a reengineering tool. So we have to deal with COBOL with embedded CICS as source code. This phenomenon makes parsing for reengineering a challenge for the compiler construction community [6] .
For IMS-DC the domain specific language is called DL/1 (Data Language/1), for CICS it is the CICS command mode language. All of the operations required from the teleprocessing monitor are addressed by means of CICS or DL/1 constructions embedded in the host language. Thus, COBOL programs were no longer really COBOL programs. They still had a basic COBOL frame and included many COBOL statements, but the average on-line program was made up by 33 to 50 percent of CICS or DL/1 commands.
It would have been easier if both teleprocessing monitors had been implemented in a similar fashion, however there is a different concept to each one. IMS is implemented as a set of subroutines similar to a class library. The user program directs the flow of control. If there is a loop or a selection to be made, it is implemented in the host language. Therefore, in the case of IMS-DC, the teleprocessing monitor operations can be handled as function invocations.
CICS is implemented as a main program similar to a framework in an object-oriented environment. It is event driven. The user does something with the keyboard and the system reacts to it. This leads to an inversion of the program: the user program itself is only a set of functions which are waiting to be invoked by CICS.
The main flow of control is outside of the program. Therefore, if there is a sequence of user functions to be executed. This sequence must be driven by the teleprocessing monitor. For this purpose IBM introduced an exception handling mechanism by means of which the user could communicate to CICS where to go next. This resulted in a pure GO TO driven flow of control, which makes CICS programs unstructured (as also stated in [20]).
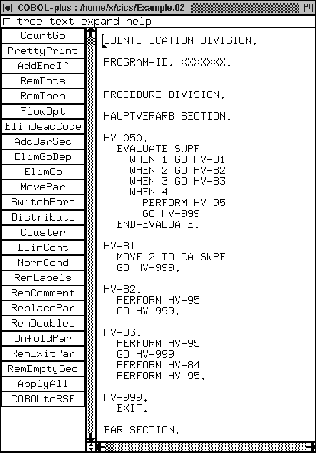
In fact, the exception handling mechanism contains implicit jump
instructions. In order to make this apparent we show the output of
a preprocessor used to translate the CICS code into COBOL code
in Figure 1. We note that such code is not for human
inspection (it may contain unprintable characters, for instance).
In the generated code of the exception handlers GO TO DEPENDING ON
logic is generated. Since this cannot be seen in the unexpanded code, we
call this an implicit jump instruction. The problematic CICS commands
are HANDLE ABEND, HANDLE AID, and HANDLE CONDITION.
We depict from these statements their result after preprocessing them with
the CICS preprocessor (module DFHECP1$). We removed unprintable
characters for the sake of ease. The preprocessor turns the original
CICS code into comments using the comment marker star. Note the
GO TO DEPENDING ON logic that pops up in the preprocessed code.
It is not important what the CICS statements in Figure 1 exactly mean, or what the equivalent preprocessed code means. Important is that the code contains implicit jumps. As a consequence, the scope of the control-flow of HANDLE statements is global. This implies that once a HANDLE command has been given, all the subsequent CICS statements can influence the control flow and suddenly jump to the specified paragraphs (A, B, C in the above examples), depending on their exit status. We note that the exit status of CICS commands is stored in a record called DFHEIGDI, that is also why the GO TO DEPENDING ON logic is looking for that variable.
When the programmer forgets about an active HANDLE command given somewhere else in the code (or in an included file), the exception handling may lead to unwanted looping behavior ([28, loc. cit. p. 143]). In order to show how complex such code can be, we give an example. In [10] a 100 KLOC COBOL/CICS system is mentioned with over 600 HANDLE commands, and some of them are in an include file that is in 9 percent of the files the first statement of a program. This indicates that implicit jump instructions are endemic in this system and are a frequent source of errors during maintenance and enhancements.
A solution to avoid the use of HANDLE commands, is to make use of the return codes that are used by CICS to deal with the exception handling. In 1987 it was still necessary to write a conversion routine to convert the return codes from hexadecimal to display characters [20]. Later IBM included after preprocessing the return codes in the WORKING-STORAGE SECTION (we did not depict this in the preprocessed code of Figure 1 because it would blur the intention the figure). The return code tells the user program what event has been invoked and allows it to make a decision as to what to do next. This is, of course, much more in time with structured programming because it allows the user program to invoke subroutines rather than jumping into specified labels with no automatic return.
Unfortunately the majority of old CICS programs were already implemented by means of the HANDLE commands long before the new return code was introduced (newer systems also use HANDLE commands). As a consequence most of the legacy CICS programs are unstructured. If they are to be made more maintainable or to be reused as objects in a distributed environment or even converted to another language such as Object-COBOL or Java, they must first be restructured [61]. That means the HANDLE commands must be removed [10,57].
The method proposed here is a two step source transformation. We explain the process with an example containing a HANDLE AID and a HANDLE CONDITION command. In the first step both HANDLE operations are commented out from the code and the decision as to what to do after each receive message is made immediately after the message is received. This is implemented by means of a COBOL EVALUATE statement which checks the states of the function keys and passes control to the labels which were contained in the original HANDLE commands. In the code fragment below, the labels are the expressions in brackets, e.g., VV-860. The first executable statement is that the RECEIVEN SECTION is to be executed. The HANDLE commands are commented out using the comment marker star by Sneed's reengineering workbench.
VV-700.
**** HANDLE AID UND CONDITION
*
* EXEC CICS HANDLE CONDITION MAPFAIL (VV-860)
* END-EXEC.
*
**** HANDLE AID 1. TEIL
*
* EXEC CICS HANDLE AID PF1 (VV-710)
* PF2 (VV-720)
* PF3 (VV-730)
* PF10 (VV-800)
* PF11 (VV-810)
* PF12 (VV-820)
* CLEAR (VV-840)
* ANYKEY (VV-850)
* END-EXEC.
**** R E C E I V E
PERFORM RECEIVEN.
**** ENTER-TASTE
MOVE 13 TO SWPF.
GO TO VV-999.
In order to be able to use the EVALUATE it is necessary to introduce some new state variables or conditional values to denote the function keys. These conditional values are declared in a copy data structure which is included in the WORKING-STORAGE SECTION. Thus, the external events, e.g. the use of function keys, are treated by the new program as a return code.
In the code fragment below, the RECEIVEN SECTION is depicted. Of course, this section depended on the HANDLE commands that are now commented out, so something must be done to preserve the behavior of the program. The exception code that was taken care of by the HANDLE commands is now being added directly below the CICS code. It is an EVALUATE that uses explicitly the COBOL programming GO TO logic. It jumps exactly to the labels that were present in the HANDLE commands.
RECEIVEN SECTION.
RE-000.
*
MOVE LOW-VALUES TO DBRIM8DI.
IF CA-SPR = 2
GO TO RE-100.
* EXEC CICS RECEIVE MAP ('DBRIM8D')
* MAPSET ('DBRIS8')
* INTO (DBRIM8DI)
* END-EXEC.
MOVE 'RC' TO X-CICS-FUNCTION
MOVE DBRIM8DI TO X-CICS-MAP
EXEC CICS LINK PROGRAM ('XTPINP')
COMMAREA (X-CICS-PARAM)
LENGTH (X-CICS-PARAM-LNG)
END-EXEC.
MOVE X-CICS-RETCODE TO EIBRESP
EVALUATE TRUE
WHEN X-MAPFAIL
GO TO VV-860
WHEN X-PF1
GO TO VV-710
WHEN X-PF2
GO TO VV-720
WHEN X-PF3
GO TO VV-730
WHEN X-PF10
GO TO VV-800
WHEN X-PF11
GO TO VV-810
WHEN X-PF12
GO TO VV-820
WHEN X-CLEAR
GO TO VV-840
WHEN X-ANYKEY
GO TO VV-850
END-EVALUATE.
GO TO RE-999.
We note that if there are more HANDLE commands that reuse labels, that the above approach should be modified. The solution becomes then a bit more complex, but the ideas behind it are the same. This concludes the first step of removing the HANDLE commands.
Obviously, after this first step the HANDLE commands have been removed, but the program is still unstructured since the GO TO branches remain. After all, we only made the implicit CICS jump instructions explicit in the COBOL programming logic. To remove them requires a second step. In this second step the flow of control going out of an EVALUATE is converted to a sequence of subroutine calls (PERFORMs in the COBOL syntax), which execute all statements on the path from the point where a message is received (the entry point) to the point where the control is passed back to the teleprocessing monitor (the exit point). This entry-to-exit path is equivalent to a control flow slice. The slices of a CICS program are both initiated and terminated by a CICS I/O operation. In principle it is possible to use binary trees to depict all possible paths leading out of an input operation. In practice it may be better to use an interactive approach in which the reengineer guides the replacement of the GO TO branches by selection and repetition structures. This second step is carried out in the next code fragment. Important to note is that the GO TOs are removed from the EVALUATE and that the relevant subroutines are listed.
RECEIVEN SECTION.
RE-000.
*
MOVE LOW-VALUES TO DBRIM8DI.
IF CA-SPR = 2
GO TO RE-100.
* EXEC CICS RECEIVE MAP ('DBRIM8D')
* MAPSET ('DBRIS8')
* INTO (DBRIM8DI)
* END-EXEC.
MOVE 'RC' TO X-CICS-FUNCTION
MOVE DBRIM8DI TO X-CICS-MAP
EXEC CICS LINK PROGRAM ('XTPINP')
COMMAREA (X-CICS-PARAM)
LENGTH (X-CICS-PARAM-LNG)
END-EXEC.
MOVE X-CICS-RETCODE TO EIBRESP
EVALUATE TRUE
WHEN X-MAPFAIL
PERFORM VV-860
PERFORM HAUPTVERARB
PERFORM FEHLMELD
PERFORM SENDFEHL
WHEN X-PF1
PERFORM VV-710
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-PF2
PERFORM VV-720
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-PF3
PERFORM VV-730
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-PF10
PERFORM VV-800
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-PF11
PERFORM VV-810
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-PF12
PERFORM VV-820
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-CLEAR
PERFORM VV-840
PERFORM HAUPTVERARB
PERFORM SENDEN
WHEN X-ANYKEY
PERFORM VV-850
PERFORM HAUPTVERARB
PERFORM SENDEN
END-EVALUATE.
* GO TO RE-999.
EXEC CICS RETURN TRANSID (CA-TRANS)
COMMAREA (COMMAREA)
LENGTH (CA-LENGTH)
END-EXEC.
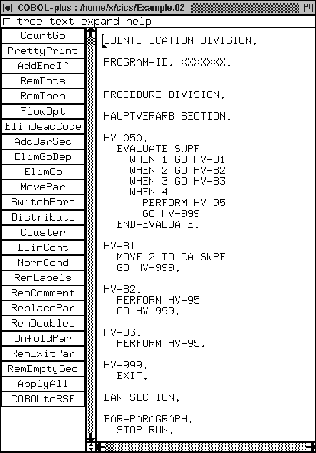
In the previous section we have seen that the first two steps took care of removal of the HANDLE commands and that the implicit GO TO logic was removed. Indeed in the above code fragment, the GO TOs are gone, however they were jump instructions due to elimination of CICS code. The next step is to remove the explicit jump instructions that were already in the code. Moreover, we remove redundant code. In this section we will discuss these steps. We give an overview of the used components. In Section 6 we will elaborately discuss the coordination of the components we introduce here. To put things in context we will already show a little in this section part of the coordination.
Figure 2 show two issues: an indication of the problematic structure of the code and an assembly line that we developed for dealing with it. The code that we see, is the start of the main program (HAUPTVERARB SECTION in German). We see 3 normal GO TOs and one DEPENDING ON jump instruction. In fact, the latter is shorthand for 16 GO TOs. So we see 19 jump instructions in this short fragment. This fragment is not exceptional for this system. Before we show the restructured code we discuss the assembly line. In Section 5.1 we discuss the components. We like to stress that the components have a complex coordination. This coordination is in fact the algorithm to remove all the GO TOs. Finally, we compare in Section 5.2 the input with the output of the algorithm. We recall that the entire coordination is subject to discussion in Section 6.
The assembly lines took 4 days of effort from development to implementation. Some pre- and postprocessing components were reused, moreover, we extended a GO TO elimination component that we discussed in [10]. Of course, all reuse speeded up development. We briefly discuss each button of Figure 2. In fact, each button is a component that we use in an algorithm to remove the GO TO logic.
The above components are used to eliminate the GO TO logic from a COBOL/CICS system. After this is done, it becomes feasible to remove redundant code. This can be dead code or indirect code. We discuss six such components.
We give a simple example. Here's two paragraphs that should be considered equal.
HV-84. **** PF4-TASTE PERFORM HV-95. HV-85. **** PF5-TASTE PERFORM HV-95.
This code is converted to the following lines of code with the ReplacePar component. Of course, all occurrences of HV-84 are replaced by references to HV-95 by this component.
HV-85. **** PF4-TASTE PERFORM HV-95. HV-85. **** PF5-TASTE PERFORM HV-95.
Te resulting code is subsequently changed into the following code by the RemDoubles component.
HV-85. **** PF4-TASTE **** PF5-TASTE PERFORM HV-95.
ReplacePar finds the PARAGRAPHs and makes their labels equal (and all references in the rest of the program). RemDoubles then removes the duplicate code and merges the comments into the remaining code.
The code changes dramatically when we apply our algorithm to the example program. So before we discuss the actual coordination of the components we give an impression of the effect the algorithm has on the code. We will discuss a few pieces of code that can be traced back to the original code that we displayed in Figure 2.
In the original code (Figure 2) we see that if CA-SCHRITT equals ZERO the control goes to HV-500. If the condition fails we will continue with paragraph HV-050 via fall-through. In the restructured code, the HAUPTVERARB SECTION has become very small: it only contains the statement that either HV-500 or HV-050 is PERFORMed. In our situation, HV-500 is a subroutine that is in the HAUPTVERARB-SUBROUTINES SECTION. Below we depicted the complete main SECTION of the restructured program.
HAUPTVERARB SECTION.
HV-000.
IF CA-SCHRITT = ZERO
PERFORM HV-500
ELSE
PERFORM HV-050
END-IF.
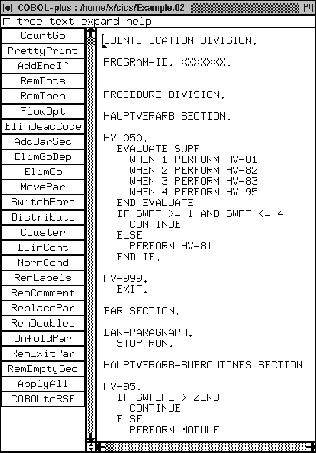
In the original program (see [47]) the HAUPTVERARB SECTION contained 206 lines of code and now we have 7 lines of code. Paragraph HV-050 is performed in the above section. It originally contained one large GO TO DEPENDING ON. This paragraph is changed into an EVALUATE statement. We depicted the code in Figure 3.
As can be seen, there was a lot of code duplication in the old code: many labels in the original GO TO DEPENDING ON statement have disappeared. We turned 16 cases into 7 in this example program, e.g., the cases 4 THRU 9 were all the same. Paragraph HV-81 (see Figure 2) is gone after restructuring, since it only jumped to HV-95. This indirect code is replaced by the (partially restructured) code below.
HV-95.
PERFORM CAFILL
IF SWFEHL > ZERO
CONTINUE
ELSE
MOVE LOW-VALUE TO DBRIM8DI
MOVE 1 TO
FEHL-NR
CA-FEHLNR
MOVE -1 TO M8SACHTL
END-IF
PERFORM HV-900.
In paragraph HV-82 of Figure 2, we see embedded CICS code followed by a GO TO HV-999. In the restructured program, this code is the same, except that the GO TO has disappeared. The reason that this is possible, is as follows. In the original code we can jump to HV-82 via the GO TO DEPENDING ON logic. Then we jump HV-999 (an EXIT paragraph). In the restructured code we use only PERFORMs. They turn back to the place where they were invoked, so after the PERFORM HV-82 is executed the control-flow is returned to the EVALUATE statement. Then, the PERFORM HV-050 is finished and the control-flow is back in the IF of the HAUPTVERARB SECTION. Via fall-through, the control-flow goes to the next SECTION. Of course, this control flow comparison of a small fragment of the code is not a proof that the algorithm we use is correct. This is just to give an indication of the dramatic impact the relatively simple components can cause. In the next section we show in detail how this impact is achieved.
In this section we will discuss the coordination of the components that we introduced in Section 5. Recall that we introduced 18 small components, each with a very specific but clear task. The trick of the algorithm is that by using the components over and over again we evolve a program from an essentially unstructured one to a well-structured program that is suited for componentization.
The algorithm resembles the architecture of so-called systolic arrays: the behavior of identical components in the small used many times resembles the same behavior but then in the large. In our case, we have several simple components, only capable of solving the most elementary form of a problem. But due to the reiterated application of such simple components together, we are able to solve the problems on a larger scale. Such an approach is also known as a systolic algorithm. There is no formal definition of systolic algorithms [43], but characteristics of it are the use of many similar cells which rhythmically compute and pass data through a system [38,39]. A typical example of a systolic algorithm is palindrome recognition. A palindrome is a word or phrase that reads the same backward or forward, like sexes. By connecting a lot of simple palindrome recognizers that can only deal with length 2 palindromes, it is possible to create a palindrome recognizer that can handle palindromes of arbitrary length [36]. Our approach is similar: we have components that can remove obviously dead code, or eliminate very easy jump instructions in favor of other more natural constructions of the language. The power of connecting those simple components and applying them over and over again leads to the removal of dead code that is much harder to detect, the elimination of much harder GO TO statements, and the elimination of GO TOs that can not be removed straightforwardly by introducing IFs or WHILE constructs.
To the best of our knowledge, the application of systolic algorithms in the area of software renovation is new. Therefore, we decided to illustrate the working of the algorithm in great detail on a small but representative example program. For a king-size example we refer to the Internet [47] where an entire production program that we restructured is present with all 70 intermediate steps and a summary of the differences between each step as generated by the Unix utility diff.
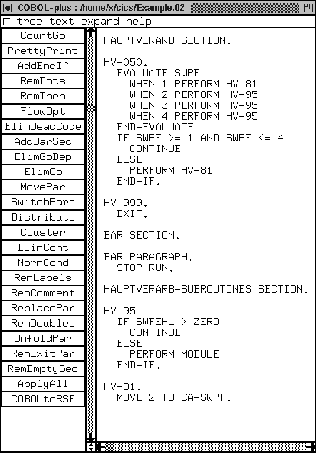
In Figure 4 we depicted a very small example containing a snippet of the real program that we published on the Internet [47]. Of course, the code snippet in Figure 4 is not a complete program. This is not a problem for illustrating the systolic structuring algorithm. For example, it does contain a limited version of the GO TO DEPENDING ON as we depicted earlier in Figure 2. How many GO TOs could you remove yourself at first glance? We think that the code fragment contains several jump instructions that are not trivial to remove so we guess that you found only a few jump instructions that can be easily removed.
The algorithm starts with preprocessing the code such that it is in good shape for the systolic part. The first step is to introduce a subroutine section for every section in the program. In Figure 5 this is illustrated. We can see that indeed not much changed in the code, except that we precooked it to be able to contain subroutines that we extract later on. We added a section with a name derived from the original section. It is suited to store subroutines in it. We put a first paragraph in it with a STOP RUN, to prevent execution of the subroutines via fall-through. Notice that the program transformation that we carried out did not introduce any semantical difference with the original program code.
In the next step we eliminate the GO TO DEPENDING ON logic. Since this statement is in fact nothing more than a case statement with as only possible cases GO TO statements, this is merely a syntax swap. The logic is not improved, it is only represented in a different manner. We have now 8 jump instructions in total in Figure 6. Note again that the semantics of the new program did not change.
The code is now massaged in such a manner that we can start to remove jump instructions. In theory, pressing the ElimGO button once, could remove all jump instructions. This only happens, however, if the use of GO TOs is restricted to simulation of conditional and iterative constructs. In practice, this is never the case. To give you an idea, in the code published on the Internet [47] the maximum number of GO TOs is 102 and after pressing the first time the ElimGO we still have 63 GO TOs left. This means that about 40 jump instructions were rather easy. In fact, we think that the average reader found only a few GO TOs in the code snippet that could be naturally removed. The rest is not so easy.
Since our ElimGO component is simple, it indeed only removes a single GO TO. The result is presented in Figure 7. Note that the difference between the former and this code is that a jump instruction has been eliminated in favor of a conditional statement.
Now we have to do something smart so that we can reuse the simple GO TO eliminator once more. What we do is we move paragraphs that do not contain jump instructions to the subroutine location. Of course we cannot just move such code around without destroying the control-flow. Therefore, we preserve the control-flow by modifying calls to this piece of code. We note that this task is not entirely trivial. In order for the reader to appreciate this, we will discuss the control-flow mechanisms of COBOL briefly. The labels introducing a paragraph in a COBOL program serve a dual purpose: first of all they are the entry-points for jump instructions. Second, they serve as scope-terminators for the previous paragraph when it is called by a subroutine call. In a way, paragraphs thus serve as subroutines. However, there is no natural mechanism like in C or Pascal where we can store subroutines and then invoke them from a main program. In COBOL, all ``subroutines'' are executed in the order they appear in the code. Although some of the readers may think that this is strange, it reflects one of the original design goals of COBOL, namely that it should be as close as possible to English (more information on the design goals of COBOL and maintenance problems is provided in [48]). Paragraphs in this text also flow from top to bottom. We all know that in order to edit a text, we can write little signs in the text and put remarks in the margins. Then we have to rewrite the text and also repair the flow when modifications are not local. The same thing happens with COBOL programs, only the signs in the code are GO TOs, and since there are no margins, the remarks become new paragraphs. Since the old version is not cleaned up as an English text, a COBOL program will contain the entire edit history of all the modifications of the previous versions. We believe that this patch mechanism is a possible cause for entangled programs: it encourages the use of jump instructions and inclusion of dead code. So we hope you realize that where to put a new subroutine without destroying the current control-flow is not at all a trivial task. So, when we start to move code around in an automated fashion we have to take care of this idiosyncratic control-flow mechanism of COBOL, too.
We proceed looking at an example. In Figure 8 we see that two paragraphs were transported to the subroutine section. They are HV-84 and HV-95. We discuss the effects on HV-95 since they are visible in Figure 8. We converted the GO TO HV-95 in the EVALUATE statement of Figure 7 to a PERFORM HV-95 statement followed by a GO TO HV-999. We use this kind of GO TO-shifting, so that the paragraphs in the SUBROUTINES SECTION are not accessible via fall-through. Thus simulating a real subroutine area comparable to other programming languages. The latter was necessary since after the original jump instruction the control-flow would not jump back to the case statement, but continue via fall-through to the EXIT paragraph. We have done the same thing on all other locations and for other labels like HV-84. Moreover the locations that formerly contained the code of the moved paragraphs are now represented by mere PERFORM statements. See the two PERFORM statements in paragraph HV-83 (Figure 8). We have put all this functionality in the component called MovePar.
During the application of the MovePar component, we introduced THEN statement connectors, to ease automated code transformations. We are going to remove them now. In Figure 9 we depicted the result of removing the THEN statement connectors. In fact, this tool could be seen as a language dependent trick. What we actually wanted to do in the former step is to turn a single statement into two statements. For, one GO TO became a PERFORM plus another GO TO. When dealing with tools that work on the underlying tree structure of a program, the result should be a correct tree again. Then a next component that is based on the grammar can deal with the tree as well. If we convert one statement into two, the resulting underlying tree of the code does not need to comply with the grammar residing in the parser. In fact, for any conversion step where the number of statements is not an invariant (of which there are many) we would then have to write some special code to still have a correct tree. Instead we split this problem into two smaller problems: first we use some grammar glue to keep the number of statements invariant, and only in a second step we apply a general purpose tool that removes the glue so that we can break up any number of glued statements into their natural parts. In this way, the number of statements stays invariant during a program transformation. In the case of COBOL the glue is natively available by means of the THEN statement connector. The language dependence in this solution is, therefore, the use of the THEN. Is it however possible to generate for any context-free grammar glue support so that also in case there is no native glueing mechanism available in the language we can still use it to simplify program transformation tasks. For more details on grammar transformations and their use we refer to [54,40]. In those papers tools and technology is explained that enables grammar extensions such that glueing support can be made available in a completely automated fashion. The usefulness of grammar glue has first been recognized by us in COBOL and the THEN statement connector materialized as a first-order approximation of a solution. Later on we generalized on the problem and recognized that structural language independent glue support is crucial if we want to make a serious case of automated code transformations. After this intermezzo we return to the algorithm, and apply the next step.
In Figure 10 we applied the ElimDeadCode component. This component is just like the simple ElimGO component a basic one. It will not remove code that appears to be dead in a very contrived way. No, it only removes code of which there is no doubt that it is dead. For instance, the last two lines of paragraph HV-83 are directly preceded by a non-conditional GO TO HV-999 (in Figure 9). Obviously the two lines of code are dead can be removed. Typically, the ElimDeadCode component will operate on code fragments that are created by other components participating in the systolic algorithm. However, the presence of dead code in the output of components means that there actually was dead code in the original program, although not that easy to see. Step-by-step restructuring will--sooner or later--place code fragments that can be recognized as dead at compile time, below an unconditional GO TO.
This answers the question that some readers might have at this point: why is that dead code over there in the program? It is so obviously dead, how can someone do this? Note that although those pieces of code will never be executed at that particular location, the code itself is not dead: it is executed from some arbitrary position in the program, and happens to be located at a location where it is not executed via fall-through. In fact this is an example of an ad hoc subroutine: it is preceded by an unconditional GO TO so there is no fall-through. We converted this ad hoc solution in a more structural solution.
Now that we have removed the obviously dead code, we have massaged the code in such a manner that again a very simple GO TO has emerged that is a perfect candidate for our simplistic ElimGO tool. The jump instruction that we refer to is the GO HV-999 which is the last line of paragraph HV-83. Since HV-999 is the adjacent paragraph, the GO TO statement is in fact totally superfluous. This is the type of GO TO that ElimGO can handle. So after pressing the button we end up with the code as we depicted it in Figure 11.
But now we created a new opportunity to move a paragraph that does not contain jump instructions to the subroutine section. It is the HV-83 paragraph. In Figure 12 we show the result of this operation: indeed, the paragraph is now in the subroutine section and on all locations where the paragraph was called we modified the code with a PERFORM and a GO TO.
We remove the THEN statement connectors again and we remove the obviously dead code. This results in the code that is depicted in Figure 13. As can be seen, we have now massaged the code again such that trivial jump instruction emerged. It is the GO HV-999 in paragraph HV-82. We note that it is not a coincidence that we end up with removing these trivial jumps each time. For, the original COBOL coders were not programming in an unstructured manner: they were deliberately coding to reach the single EXIT of a section. After numerous stages of maintenance, it took many intermediate steps to get there, and the more maintenance had been done on such code, the more intricate the jumping behavior tended to become. If you do not use subroutines, but still have to add new code, you have to put it somewhere. This often implies that it is put on some arbitrary hopefully save location and that with the use of jump instructions the original control-flow is maintained. What we in fact do with this systolic structuring algorithm is to roll back the coding history and saving the cleansed paragraphs to a subroutine section and thus simulating a programming language that has native support for subroutines. As soon as we put the subroutines in a logical place where ordering does not matter since we do cannot access the code via fall-through, we are on our way to solve the code location problem. Moreover, by unraveling the code in such a way, more and more of the structured code will pop up, and the simple GO TOs will emerge, one at a time. And those can be removed in a trivial way.
All in all, we can again use the MovePar button to transport the the next piece of structured code to a save haven. Again we have to remove the THENs and remove the obviously dead code. Some readers might think: we have not seen the RemDots component that was discussed in Section 5. This is true. Of course when we move code around, we will now and then introduce separator periods on locations that should be removed. In the components that can introduce dots, like the MovePar component, we call internally the RemDots component to clean up the small things like separator periods. We did not mention this before since we want to show the heartbeat of the algorithm and not focus on the smallest details simultaneously.
The result is visible in Figure 14. As we can see in this display, we have again a simple jump instruction that we can just remove with the ElimGO button. The result is displayed in Figure 15.
We can fruitfully apply the MovePar button to move paragraph HV-81 to the subroutine section as well. This is shown in Figure 16.
At this moment we cannot just continue with the systolic algorithm and remove more jump instructions: there are no more easy GO TOs in the code. As we can see in Figure 16 the only jumps that are left all reside inside the EVALUATE statement. In Figure 16 the paragraph moving operations have revealed that the distinct jump instructions in the GO TO DEPENDING ON that we originally started with, are all reduced to GO TO HV-999. The intermediate steps that were put in the program, are now represented by PERFORM statements. In the case of this small example program for each case there is one PERFORM statement.
Next we distribute the GO HV-999 out of the case statement: after all, in all cases this statement will be applied. We press the Distribute button. The effect is that the clauses of the EVALUATE are all combined, and adjacent to the case statement an IF is plugged in containing the common GO TO statement. The result of the transformation is shown in Figure 17. Of course we have to remove THEN statement connectors and the obviously dead code (if any), before we can continue with the GO TO removal as usual.
In Figure 18 we have depicted the result of pressing the ElimGO button again. As can be seen from the code: the very first GO TO that was eliminated in this example had exactly the same pattern as the one we removed here. So at this point we have removed all GO TO statements. In the case of the program that we put on the Internet [47], we needed about 60 to 70 steps to come to the point where all GO TOs were gone.
Of course, our ultimate goal was not to just remove jump instructions (as indicated in Section 2), but to massage the code in such a way that we can reuse it in a component-based context. We have seen that the control-flow of the code was not at all optimal. Of course this has not been fully solved by our systolic algorithm. In fact the code suffers still from a lot of indirect jumping, albeit that it is no longer expressed by GO TOs. Consider, for example, in the original program (see Figure 4) paragraph HV-82. In that paragraph we only jump to HV-95 which we could have done that more directly, by jumping to that paragraph from the start. We have not (yet) solved that issue in the beginning since we wanted to focus on one problem at a time. But now the time has come. We implemented a simple tool called UnfoldPar that removes such indirect code and replaces it with more direct code. The tool is now relatively simple to implement since we do not need to take the possibility of weird jumps into account. The resulting output of this tool is presented in Figure 19. As can be seen, from the four cases in the EVALUATE there are only two left: HV-81 and HV-95. In the large program we put on the Internet [47] we went from 16 cases to 7 (see Figure 3). Also note that in the subroutine section there are just two paragraphs left. Both paragraphs contain something real, one could call such paragraphs candidates for business logic. In the simulated main section the coordination of the business logic resides. In fact, our algorithm is a prerequisite to detect business logic in source code without going to a higher abstraction level. We make the coordination of candidate business logic transparent. Then we can inspect all the paragraphs one by one. We can modify the coordination. Moreover, we can insert new subroutines, modify old ones, and delete subroutines without affecting the control-flow. This means that the programs have become modular, change-enabled, and in a sense componentized since only part of the functionality can be invoked at wish.
We use a special-purpose transformation that cleans up the EVALUATE statement and eliminates case clones by combining the WHEN clauses. The result is displayed in Figure 20.
We postprocess the code and shape it up as much as possible. First we remove all CONTINUE statements that were introduced during the other program transformations. The result is visible in Figure 21.
Of course, the former transformation affected conditionals, and also earlier program transformations made changes to the conditionals, just think of the WHEN clause clustering. We shape up these logically challenged conditionals. The result of pressing the NormCond button is depicted in Figure 22. For instance, WHEN 4 OR 3 OR 2 was converted to 2 THRU 4, and NOT ( SWFEHL > ZERO) normalized to SWFEHL <= ZERO, and so on.
Finally, we can get rid of the EXIT paragraph. We recall that the EXIT has no semantic meaning. It is introduced as a type of comment so that programmers could keep track where to jump to in the end so that each section would have one exit location. We have converted to a completely different paradigm for control-flow. Namely in the HAUPTVERARB section we only have coordination code and in the subroutines section we have calculations. So the control-structure is entirely different. The EXIT paragraph as no goal anymore, and since it has no semantics as well, we can just remove it. We do this with the RemExitPar button; the resulting code is depicted in Figure 23.
Until now the coordination of the components was discussed in an implicit manner. We discuss here the full picture. Of course, we do not want to interactively restructure all the programs, so we take the automation of the restructuring a step further by giving the coordination of the components for the general case. It will turn out that the coordination is so regular that it can be automated. The coordination of the components has three main phases: preprocessing, main processing and postprocessing. We discuss them below.
Once we ran all these tools, we have removed a lot of irregularities so that the main processing can commence.
In a production environment, we combine certain pre- and postprocessing tools into more involved components, i.e., we already know that the MovePar will probably reveal dead code, so we have built-in this postprocessing component in the production version of the MovePar. In general, the more complex components are themselves small assembly lines: they start with preprocessing, then they do their thing, and then things are cleaned up in a small postprocessing step. If we in the sequel talk about components like ElimGO or MovePar we talk about the production versions.
First of all, we alternately run ElimGO and MovePar until the code does not change anymore. If this is the case we either do not have any GO TO left, or we do have them. Do not worry, usually you still have them. Then we break out of the loop and try the Distribute if there was a GO TO DEPENDING ON in the original program, which probably moves a common GO TO out of its body. Also the Distribute component is in the production environment enriched with pre and postprocessing components. Then we continue with the ElimGO, MovePar array. If we are again stuck and not ready, and there is no common jump instruction to be extracted from case statements, we use a trick. Sometimes the code is so entangled that it becomes in a way easy to move paragraphs around. In fact, when both programmer and program reached this Gordian knot nirvana, they both become enlightened. For, there is almost a 100% chance that if you put the code on an arbitrary location with many GO TOs in the neighborhood, the control-flow is not affected. As the same time there is an almost 0% chance that anyone understands why this is the case. However, in a few cases, there is a simple automated check that ensures this even. To get the idea: think of pieces of code that are entirely separated by unconditional jump instructions at the end. In fact, we use these ultra bad parts of the code to move a paragraph with a jump back to a distant location nearer to its entry-point label. Hopefully above it, since then the ElimGO component can probably deal with it. So when all else fails and there are still GO TO statements, invoke SwitchPars which will switch code around in the hope that we can reenter the ElimGO, MovePar loop. Note that we are not at all claiming that this systolic algorithm will remove all jump instructions from all programs. We only claim that for all the practical cases that we encountered we could remove them using this algorithm. We are pretty confident that sooner or later there will be a program that asks for adaptation of this algorithm.
In any case, as soon as the GOs are gone, we can start to postprocess the code.
Just like the preprocessing these postprocessing components are also applied in a pipeline.
We depict a visualization of the coordination of the components of the program we published on the Internet [47]. This program is called DBRIP08.COB (given the quality of the code, the most appropriate meaning of this abbreviations is: Database, Rest in Peace). In Figure 24 the application of the components is at the vertical axis, and the consecutive steps are on the horizontal axis. The curve represents the heartbeat of the systolic structuring algorithm. We call such diagrams sometimes ``cardiograms''. The three main phases can readily be detected from the form of the curve. The irregularities during the repetitive part are clearly visible in the graph. We note that the cardiogram of the example that we presented in full resembles the curve of Figure 24 (it is only shorter).
So using the explained coordination of the components we can automate the interactive session that we discussed in this section. We implemented this functionality in the ApplyAll button. We used the coordination language SEAL [34,35] for that.
Once the CICS code has been restructured to be driven by return codes rather than by branching to given labels it is possible to repartition it. Repartitioning involves the extraction of subroutines on the SECTION level from the original source text where they are performed in-line and their replacement by subprograms which are called dynamically at run time. This repartitioning has the advantage of making the CICS programs much smaller, more flexible, more testable and more easy to maintain [58].
A repartitioned program is of course much smaller because only the CICS commands and the control logic are left in the main program. The processing routines are removed to separate modules. Such programs are more flexible because it is now possible to change the transaction control without affecting the processing logic. They are more testable because each processing routine, i.e. each sliced segment, can be tested separately. By stubbing out subprogram calls it is also possible to test the transaction control logic separately without the processing. Finally, the program is easier to maintain because the interfaces have been clearly specified and the processing units have been isolated from the transaction control. In effect, repartitioning aims at a complete separation of coordination and computation. In [5] such strategies are considered being core technologies for system renovation. Note that in Sections 5 and 6 coordination and computation are also separated which enables flexible (re)use of components.
The repartitioning process is accomplished in three passes. In the first pass a data flow analysis is performed to determine which variables are used in what way in each subroutine, i.e. performed PARAGRAPH or SECTION. These variables are stored in a data reference table for each subroutine. In the second pass the subroutines are cut out of the original source code and placed in the procedural part of a module framework. The variables they use are defined as parameters in the LINKAGE SECTION and are listed in the entry command. In this way each subroutine becomes a separate subprogram. In the third pass the main program is processed again to convert all PERFORMs to subroutines into CALL USING commands. The CALL is made to a variable name which is assigned before the name of the subroutine. This type of dynamic linking is better supported by CICS as it avoids having to run a static link job. The parameters of the CALL statement are filled with the variables used by that particular subroutine. We give the shortest example that was available in the code. We see that the VERARB SECTION that was performed is now put in a subprogram. In that subprogram a paragraph dbrip002 is called that uses all the data that was found during the data flow analysis in the first step.
* PERFORM VERARB
CALL "dbrip002" USING
COMMAREA,
RECHENFELDER,
ARBEITSDATEN,
DFHBMBRY,
DBRIM8DI,
XM181-P,
SWITCHES,
P-XM314,
KONSTANTEN,
P-XM200,
P-P008L.
The result of the repartitioning process is a modular CICS program consisting of a main control module with the transaction processing logic and processing submodules which implement the business logic. A next step could be to separate out the access logic, but that topic deserves a separate paper.
In order to repartition for migration to other platforms, it is important to remove all CICS commands. Therefore, the normal CICS commands are substituted by CALLs like the preprocessor as discussed in Section 3.1. We give an example of a CICS statement that can be equally well expressed using standard COBOL.
* EXEC CICS LINK * PROGRAM ( 'D154' ) * END-EXEC. CALL 'D154'.
The CICS statement is commented out (using the comment marker *) and a standard COBOL CALL is replacing the CICS. This kind of CICS elimination makes the program more portable to other environments. Of course, CICS is available on many platforms, so this step is not always necessary.
CICS programs communicate with one another via a global data area referred to as the communication area--in COBOL syntax the COMMAREA. Here data may be deposited by one program and picked up by another one. This kind of global coupling is dangerous and may produce undesired side-effects, particularly if pointers are being used. To access the communication area CICS programs are passed a pointer as a parameter. All references to data within that area are subsequently made by computing the displacement from that start address. User programs usually include a COPY data structure describing the entire communication area even though the program only uses a few variables. Not only has the size of the program exploded, but the program is given access to data which it should not see. This is a blatant violation of the principle of information hiding and a frequent cause of undesirable side-effects [44]. The user can easily overwrite data that does not belong to him or her. The error will only be recognized later in some successor program.
Such addressing techniques must be eliminated if CICS programs are to be reused in another environment. For this reason, all of the data referenced within a module should be placed in an explicit parameter list, even if this list becomes long. It is the lesser of two evils. Either one has to create a similar global data area in the new environment or one creates parameter lists. The solution selected here is to generate a list of parameters, one for each structure and elementary data type referred to by the module. These parameters can then be set by any client program calling the module in question.
By placing all of the data used by a module in its linkage section, the module becomes stateless, that is, it has no own memory. In this way reentrancy is assured and the module is detached from its data [58]. The data may reside somewhere in a buffer within the wrapper. From there it should be passed by value, meaning that only a copy of the values are provided to the module called and only those values which it really processes. This greatly reduces the risk of side-effects and makes the repartioned CICS program much more flexible. Later modules of this type can be readily converted to methods as prescribed in the new Object COBOL standard [2,26]. In the code below we give an impression of what this looks like. We show the long LINKAGE SECTION on purpose so that the realities of paradigm shifts become apparent, and note that this is the lesser of two eveils.
****************************************************************** * VERARBEITUNG ****************************************************************** * METHOD-ID. "dbrip002". DATA DIVISION. LINKAGE SECTION. 01 RECHENFELDER. 05 R-ADRSW PIC 9(3) VALUE ZERO. 05 R-LEERZ PIC 9(3) VALUE ZERO. 05 R-RNW PIC S9(5)V99 VALUE ZERO. 05 R-RATE PIC S9(7)V99 VALUE ZERO COMP-3. 05 R-REST PIC S9(5)V9999 VALUE ZERO. 01 ARBEITSDATEN. 02 M8CANA PIC X. 02 M8XJUMPA PIC X(8). 01 DFHBMBRY PIC X(8). 01 DBRIM8DI. 02 FILLER PIC X(40). 02 M8PRIDI PIC X(8). 02 M8PRIDL PIC 99. 02 M8PRIDF PIC X. 02 M8CANI PIC X(8). 02 M8CANL PIC 99. 02 M8CANF PIC X. 02 M8ABS1I PIC X(8). 02 M8ABS1L PIC 99. 02 M8ABS1F PIC X. 02 M8ABS2I PIC X. 02 M8ABS2L PIC 99. 02 M8ABS2F PIC X. 02 M8ABS3I PIC X. 02 M8ABS3L PIC 99. 02 M8ABS3F PIC X. 02 M8ABS4I PIC X. 02 M8ABS4L PIC 99. 02 M8ABS4F PIC X. 02 M8ADRZ1I PIC X. 02 M8ADRZ1L PIC 99. 02 M8ADRZ1F PIC X. 02 M8ADRZ2I PIC X. 02 M8ADRZ2L PIC 99. 02 M8ADRZ2F PIC X. 02 M8ADRZ3I PIC X. 02 M8ADRZ3L PIC 99. 02 M8ADRZ3F PIC X. 02 M8ADRZ4I PIC X. 02 M8ADRZ4L PIC 99. 02 M8ADRZ4F PIC X. 02 M8ADRZ5I PIC X. 02 M8ADRZ5L PIC 99. 02 M8ADRZ5F PIC X. 02 M8ADSW1I PIC X. 02 M8ADSW1L PIC 99. 02 M8ADSW1F PIC X. 02 M8ADSW2I PIC X. 02 M8ADSW2L PIC 99. 02 M8ADSW2F PIC X. 02 M8ADSW3I PIC X. 02 M8ADSW3L PIC 99. 02 M8ADSW3F PIC X. 02 M8ADSW4I PIC X. 02 M8ADSW4L PIC 99. 02 M8ADSW4F PIC X. 02 M8SACHTI PIC X. 02 M8SACHTL PIC 99. 02 M8SACHTF PIC X. 02 M8SACH1I PIC X. 02 M8SACH1L PIC 99. 02 M8SACH1F PIC X. 02 M8SACH2I PIC X. 02 M8SACH2L PIC 99. 02 M8SACH2F PIC X. 02 M8ANREDI PIC X. 02 M8ANREDL PIC 99. 02 M8ANREDF PIC X. 02 M8ERDATI PIC XXXXXX. 02 M8ERDATL PIC 99. 02 M8ERDATF PIC X. 02 M8MENDZI PIC XXXXXX. 02 M8MENDZL PIC 99. 02 M8MENDZF PIC X. 02 M8MENDVI PIC XXXXXX. 02 M8MENDVL PIC 99. 02 M8MENDVF PIC X. 02 M8OBJI PIC XXXX. 02 M8OBJL PIC 99. 02 M8OBJF PIC X. 02 M8UEBETI PIC X. 02 M8UEBETL PIC 99. 02 M8UEBETF PIC X. 02 M8KAUTII PIC X. 02 M8KAUTIL PIC 99. 02 M8KAUTIF PIC X. 02 M8ZGUTI PIC X. 02 M8ZGUTL PIC 99. 02 M8ZGUTF PIC X. 02 M8ANZRAI PIC X. 02 M8ANZRAL PIC 99. 02 M8ANZRAF PIC X. 02 M8RATEI PIC X. 02 M8RATEL PIC 99. 02 M8RATEF PIC X. 02 M8FZ1I PIC X. 02 M8FZ1L PIC 99. 02 M8FZ1F PIC X. 02 M8FZ2I PIC X. 02 M8FZ2L PIC 99. 02 M8FZ2F PIC X. 02 M8FZ3I PIC X. 02 M8FZ3L PIC 99. 02 M8FZ3F PIC X. 02 M8XJUMPI PIC X. 02 M8XJUMPL PIC 99. 02 M8FJUMPF PIC X. 01 XM181-P. 05 XM181-1. 10 FEHL-NR PIC 9999 VALUE 0. 10 FEHL-SPR PIC 9. 05 XM181-2. 10 XM181-PROG PIC X(8). 05 XM181-3. 10 FEHL-MELD PIC X(79). 05 XM181-4. 10 FEHL-VAR1 PIC X(20). 05 XM181-5. 10 FEHL-VAR2 PIC X(20). 05 XM181-6. 10 FEHL-VAR3 PIC X(20). 05 XM181-7. 10 FEHL-VAR4 PIC X(20). 05 XM181-8. 10 FEHL-VAR5 PIC X(20). 05 XM181-9. 10 FEHL-VAR6 PIC X(20). 01 P-XM314. 05 P1-XM314. 10 P1-XM314-EL OCCURS 5. 15 P1-XM314-ADRSW PIC X. 15 P1-XM314-ADRZ PIC X(30). 05 P2-XM314. 10 P2-XM314-1 PIC X. 10 P2-XM314-2 PIC X. 10 P2-XM314-3 PIC 9(4) COMP. 10 P2-XM314-4 PIC 9(4) COMP. 10 P2-XM314-5 PIC X(8). 01 P-XM200. 05 P200-1 PIC X(8). 01 P-P008L PIC S9(4) COMP. 01 P-P008. 05 P008-1 PIC S9(8) COMP. PROCEDURE DIVISION USING INOUT RECHENFELDER, OUTPUT ARBEITSDATEN, INPUT DFHBMBRY, OUTPUT DBRIM8DI, OUTPUT XM181-P, OUTPUT P-XM314, OUTPUT P-XM200, INOUT P-P008L, INOUT P-P008. ***************************************************************
We briefly discuss the pros and cons of our approach. First of all, we replaced the CICS commands by CALLs to a wrapper. In this case the programs can be executed in any environment provided the wrapper is able to fulfill the requests. Moreover, the user interface can be implemented totally independent of the old program, for instance in Java. The wrapper could be implemented in C++. Everything can be connected with an object request broker using OMA's Interface Definition Language to define the interfaces.
Second, we removed all GO TO logic. We have argued in the introduction that this makes the system easier to maintain and test, irrespective of what environment it is running in. Another benefit is that the code decreases in size.
We stress that the problem with old COBOL programs is that any one section of code will address data elements scattered throughout the DATA DIVISION, that is, they use global data. This results in long parameter lists when we are going to remodularize. There is nothing that can be done to prevent this. If we would pass individual data elements instead of structures, the lists are even longer. This is the problem of dealing with real programs instead of models of programs created for research purposes. Thus, we create complex interfaces for the subprograms, which may be seen as more problematic than in-line solutions. The first two steps we are certainly cost-beneficial, as argued in the introduction. But not applied as such as argued in Section 2. Our last step is debatable, since the advantage of subprograms might be annihilated by the creation of the complex interfaces. However, if we have to access COBOL/CICS legacy applications in a modular way from the outside we have little choice but to use the complex interfaces.
Embedded CICS on-line programs have a unique event driven structure irrespective of what host language they use. The CICS commands are normally scattered throughout the source for controlling the interaction with the user as well as for the data access. The host code in which the CICS commands are embedded only serves to describe the data structures and to process them when they are made available by CICS. As a rule this processing logic is unstructured. If the processing logic is to be separated from the presentation and the access logic as is required by modern software architectures, then the CICS commands which return control from the user to specified code locations must be removed and replaced by a return value. In addition, the user code must be restructured to perform subroutines based on this return value rather than by branching directly to given labels. Only when this is done, will it be possible to migrate or wrap CICS on-line programs.
The research described in this paper is intended to solve the problem of restructuring CICS programs in order to make them more maintainable and to facilitate the migration into different environments such as to a client/server platform.
Bibliography
Component-Based Development for Enterprise Systems.
Cambridge University Press, 1998.
Object-Oriented COBOL.
SIGS Books, 1996.
Restructuring eases maintenance.
Computerworld, page 19 and 22, November 1987.
Software Engineering Economics.
Prentice Hall, 1981.
Core technologies for system renovation.
In K.G. Jeffery, J. Král, and M. Bartosek, editors, SOFSEM'96: Theory and Practice of Informatics, volume 1175 of LNCS,
pages 235-255. Springer-Verlag, 1996.
Available at http://adam.wins.uva.nl/~x/sofsem/sofsem.html.
Re-engineering needs generic programming language technology.
ACM SIGPLAN Notices, 32(2):54-61, 1997.
Term rewriting for sale.
In C. Kirchner and H. Kirchner, editors, Second International
Workshop on Rewriting Logic and its Applications, Electronic Notes in
Theoretical Computer Science. Springer-Verlag, 1998.
Available at: http://adam.wins.uva.nl/~x/sale/sale.html.
Generation of components for software renovation factories from
context-free grammars.
In I.D. Baxter, A. Quilici, and C. Verhoef, editors, Proceedings
of the Fourth Working Conference on Reverse Engineering, pages 144-153,
1997.
Available at http://adam.wins.uva.nl/~x/trans/trans.html.
Obtaining a COBOL grammar from legacy code for reengineering
purposes.
In M.P.A. Sellink, editor, Proceedings of the 2nd International
Workshop on the Theory and Practice of Algebraic Specifications, Electronic
Workshops in Computing. Springer verlag, 1997.
Available at http://adam.wins.uva.nl/~x/coboldef/coboldef.html.
Control flow normalization for COBOL/CICS legacy systems.
In P. Nesi and F. Lehner, editors, Proceedings of the Second
Euromicro Conference on Maintenance and Reengineering, pages 11-19, 1998.
Available at http://adam.wins.uva.nl/~x/cfn/cfn.html.
Current parsing techniques in software renovation considered harmful.
In S. Tilley and G. Visaggio, editors, Proceedings of the sixth
International Workshop on Program Comprehension, pages 108-117, 1998.
Available at http://adam.wins.uva.nl/~x/ref/ref.html.
Generation of components for software renovation factories from
context-free grammars.
Science of Computer Programming, 36(2-3):209-266, 2000.
Available at http://adam.wins.uva.nl/~x/scp/scp.html. An extended
abstract with the same title appeared earlier: [8].
Generation of formatters for context-free languages.
ACM Transactions on Software Engineering and Methodology,
5:1-41, 1996.
Automatic compiler restructuring of COBOL programs into a proc per
paragraph model.
U.S. Patent No. 5,778,232, Jul. 7, 1998.
IBM's Workstation CICS.
McGraw-Hill, 1992.
Objects, Components, and Frameworks With UML - The Catalysis
Approach.
Object Technology Series. Addison-Wesley, 1998.
Component-Based Software Engineering.
IEEE Computer Society Press, 1996.
Parallel Test and Productivity Evaluation of a Commercially
Supplied COBOL Restructuring Tool.
Technical report, Office of Software Development and Intormation
Technology, Falls Church, Virginia, USA, 1987.
Handbook of Walkthroughs, Inspections and Technical Reviews.
Dorset House, 3rd edition, 1990.
Originally published by Little, Brown & Company, 1982.
An alternative to CICS HANDLE commands.
CICS Update, July 1987.
Accessing legacy systems.
Object Expert, 5(3):58-60, 1997.
Transformations to restructure and re-engineer COBOL programs.
Journal of Automated Software Engineering, 5:321-345, 1998.
Applying formal specification to software development in industry.
IEEE Transactions on Software Engineering, SE-11(2):169-178,
1985.
CICS/ESA Application Programming Reference, 1992.
AOC/MVS IMS Automation Programmer's Reference and Installation
Guide, 1.3 edition, 1994.
Programming Language COBOL, 1.8 edition, 2000.
Available at http://www.ncits.org/tc_home/j4htm/cd18all.pdf.
CICS HANDLE commands versus RESP/RESP2.
CICS Update, November 1987.
CICS Command Level Programming.
Wiley Professional Computing, 1991.
Assessment and Control of Software Risks.
Prentice-Hall, 1994.
Estimating Software Costs.
McGraw-Hill, 1998.
The Year 2000 Software Problem - Quantifying the Costs and
Assessing the Consequences.
Addison-Wesley, 1998.
Mainframe application migration using P/370 technology.
Enterprise Systems Journal, May 1995.
Evolutionary software engineering: A component-based approach.
In R.N. Horspool, editor, IFIP WG 2.4 Working Conference:
Systems Implementation 2000: Languages, Methods and Tools, pages 1-18.
Chapman & Hall, 1998.
Available at: http://adam.wins.uva.nl/~x/evol-se/evol-se.html.
Connecting semantic tools to a syntax-directed user-interface.
In H.A. Wijshoff, editor, Computing Science in the Netherlands
(CSN93), SION, pages 217-228, 1993.
Generating uniform user-interfaces for interactive programming
environments.
PhD thesis, University of Amsterdam, 1994.
Correctness proofs for systolic algorithms: palindromes and sorting.
In J.C.M. Baeten, editor, Applications of Process Algebra,
Cambridge Tracts in Theoretical Computer Science 17, pages 89-125. Cambridge
University Press, 1990.
On the re-engineering of transaction systems.
Journal of Software Maintenance, 4(3):143-162, 1992.
Systolic Arrays (for VLSI).
In I.S. Duff and G.W. Stewart, editors, Sparse Matrix
Proceedings 1978, pages 256-282. Society for Industrial and Applied
Mathematics, Philadelphia, PA (USA), 1979.
Systolic array apparatuses for matrix computations.
U.S. Patent No. 4,493,048, Jan. 8, 1985.
Semi-automatic grammar recovery.
Technical Report P2000, University of Amsterdam, Programming Research
Group, 2000.
Available at: http://adam.wins.uva.nl/~x/ge/ge.html.
Software Maintenance Management--A Study of the Maintenance of
Computer Application Software in 487 Data Processing Organizations.
Reading MA: Addison-Wesley, 1980.
Rapid Development.
Microsoft Press, 1996.
Matrix Computations on Systolic-Type Arrays.
Kluwer Academic Publishers, 1992.
The criteria to be used in decomposing systems into modules.
Communications of the ACM, 15(12):1053-1058, December 1972.
Measures for Excellence - Reliable Software on Time, Within
Budget.
Yourdon Press Computing Series, 1992.
Maintenance is a management problem and a programmer's opportunity.
In A. Orden and M. Evens, editors, 1981 National Computer
Conference, volume 50 of AFIPS Conference Proceedings, pages 343-347.
AFIPS Press, Arlington, VA, 1981.
Systolic structuring algorithm in steps, 1998.
Available at http://adam.wins.uva.nl/~x/systolic/systolic.html.
Reflections on the evolution of COBOL.
Technical Report P9721, University of Amsterdam, 1997.
Available at http://adam.wins.uva.nl/~x/lib/lib.html.
Development, assessment, and reengineering of language descriptions
- extended abstract.
In B. Nuseibeh, D. Redmiles, and A. Quilici, editors, Proceedings of the 13th International Automated Software Engineering
Conference, pages 314-317, 1998.
For a full version see [53]. Available at:
http://adam.wins.uva.nl/~x/ase98/ase98.html.
Native patterns.
In M. Blaha, A. Quilici, and C. Verhoef, editors, Proceedings of
the 5th Working Conference on Reverse Engineering, pages 89-103. IEEE
Computer Scociety Press, 1998.
Available at http://adam.wins.uva.nl/~x/npl/npl.html.
An Architecture for Automated Software Maintenance.
In D. Smith and S.G. Woods, editors, Proceedings of the Seventh
International Workshop on Program Comprehension, pages 38-48. IEEE Computer
Society Press, 1999.
Available at http://adam.wins.uva.nl/~x/asm/asm.html.
Generation of software renovation factories from compilers.
In H. Yang and L. White, editors, Proceedings of the
International Conference on Software Maintenance, pages 245-255. IEEE
Computer Society Press, 1999.
Available via http://adam.wins.uva.nl/~x/com/com.html.
Development, assessment, and reengineering of language descriptions.
In J. Ebert and C. Verhoef, editors, Proceedings of the Fourth
European Conference on Software Maintenance and Reengineering, pages
151-160. IEEE Computer Society, March 2000.
Full version of [49]. Available at:
http://adam.wins.uva.nl/~x/cale/cale.html.
Scaffolding for software renovation.
In J. Ebert and C. Verhoef, editors, Proceedings of the Fourth
European Conference on Software Maintenance and Reengineering, pages
161-172. IEEE Computer Society Press, March 2000.
Available via http://adam.wins.uva.nl/~x/scaf/scaf.html.
Economics of software reengineering.
Journal of Software Maintenance, 3(3):163-182, 1991.
Architecture and functions of a commercial software reengineering
workbench.
In P. Nesi and F. Lehner, editors, Proceedings of the Second
Euromicro Conference on Maintenance and Reengineering, pages 2-10. IEEE
Computer Society, 1998.
Object-oriented Software Migration.
Addison-Wesley, October 1998.
Downsizing large application programs.
Journal of Software Maintenance, 6(5):235-247, 1994.
Understanding Z: A Specification Language and Its Formal
Semantics.
Cambridge Tracts in Theoretical Computer Science 3. Cambridge
University Press, 1988.
The Z Notation: A Reference Manual.
Prentice-Hall, 1992.
The realities of language conversions.
IEEE Software, 2000.
To Appear. Available at http://adam.wins.uva.nl/~x/cnv/cnv.html.
![]()
![]()
![]()
Chris Verhoef
2000-05-16