 |



René Krikhaar*,
André Postma*,
Alex Sellink**,
Marc Stroucken*,
Chris Verhoef**
*Philips Research Laboratories, Prof. Holstlaan 4
(WL01),
5656 AA Eindhoven, The Netherlands
**University of Amsterdam,
Programming Research Group
Kruislaan 403, 1098 SJ Amsterdam, The Netherlands
{krikhaar,postmaa,strouckn}@natlab.research.philips.com,
{alex|x}@wins.uva.nl
Software architecture is important for large systems in which it is the main means for, among other things, controlling complexity. Current ideas on software architectures were not available more than ten years ago. Software developed at that time has been deteriorating from an architectural point of view over the years, as a result of adaptations made in the software because of changing system requirements. Parts of the old software are nevertheless still being used in new product lines. To make changes in that software, like adding features, it is imperative to first adapt the software to accommodate those changes. Architecture improvement of existing software is therefore becoming more and more important.
This paper describes a two-phase process for software architecture improvement, which is the synthesis of two research areas: the architecture visualisation and analysis area of Philips Research, and the transformation engines and renovation factories area of the University of Amsterdam. Software architecture transformation plays an important role, and is to our knowledge a new research topic. Phase one of the process is based on Relation Partition Algebra (RPA). By lifting the information to higher levels of abstraction and calculating metrics over the system, all kinds of quality aspects can be investigated. Phase two is based on formal transformation techniques on abstract syntax trees. The software architecture improvement process allows for a fast feedback loop on results, without the need to deal with the complete software and without any interference with the normal development process.
Keywords: software architecture, software recovery, software rearchitecting, software architecture transformation
Royal Philips Electronics N.V. is a world-wide company that develops low-volume professional systems (such as communication systems and medical systems) and high-volume consumer electronics systems (like digital set-top boxes and television sets). Software plays an increasingly important role in all these systems.
In the domain of high-volume electronics the point has been reached at which it is no longer possible to develop each new product from scratch. The software architecture of new products is of great importance with respect to satisfying the demands for increasing functionality with decreasing time-to-market. Design for reuse and open architectures are of the utmost importance with respect to software architectures for product lines [BCK98].
In the domain of professional systems this turning point was already reached more than ten years ago. At the time when these large software systems were developed, most of the current software architecture techniques were not available. The old software is nevertheless still used in the development of new products. Current products are more and more feature-driven, and must therefore meet high requirements with respect to the flexibility and maintainability of the software.
Since we want to accommodate future changes in the software in both domains, there is a need for software architecture improvement. This paper describes a new software architecture improvement process that combines two research areas.
The main topic of this paper is the description of a two-phase process for recovering and improving software architectures, with a clear distinction between architecture impact analysis (phase one) and software architecture transformations (phase two). Architecture impact analysis uses a model based on Relation Partition Algebra (RPA [FO94,FKO98,FO99,FK99]). Software architecture transformations use formal transformation techniques, and aim at modifying the software to meet the new architecture requirements [BKV96,BSV97,SV98,BKV98,DKV99,SV99a,SV99b,SV99c,SV99d].
The paper is structured as follows. In Section 2 a general description of the process for software architecture improvement is given. Section 3 describes an example to illustrate this process. In Section 4 issues related to architecture impact analysis are discussed. Section 5 focuses on the software architecture transformations and describes ideas for a set of basic transformations that are of interest for these kinds of software architecture improvements. Finally, related work is described and some conclusions are given.
The authors would like to thank Reinder Bril, Loe Feijs, Peter van den Hamer, Jaap van der Heijden and Joachim Trescher for reviewing previous versions, and the fruitful discussions that helped us to improve this paper.
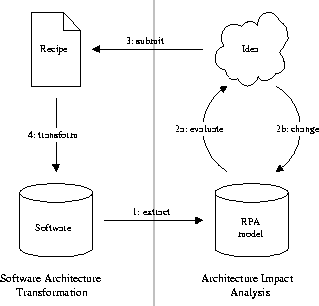
The process which in our opinion can answer these questions is depicted in Figure 1. Before we give a detailed description of the steps, we will give some definitions and assumptions on which this process is based. We adhere to the terminology proposed by Chikofsky and Cross [CC90].
To improve software architecture we must first have a described software architecture, which is an explicit description of requirements of the system from a software architecture point of view [SNH95,Kru95]. For large software systems a software architecture description is usually not available. Software architecture recovery or reverse architecting [Kri97,Kri99] is the process that extracts such a description from the software.
Rearchitecting is the process of changing the software architecture. Software architecture improvement is the process that makes changes in the architecture in such a way that it improves the software in one or more of its quality aspects. Quality aspects are for instance the comprehensibility of the software for the developers, the extensibility of the software with new features and the reusability of its parts. Quality aspects are usually accompanied by metrics. Using the proper metrics we can measure improvement by comparing the values before and after the change. Defining good metrics is a research topic beyond the scope of this paper. To experiment with different kinds of metrics and changes we need a good process, supported by tooling.
Changes can affect many parts of the software. Before a change is executed, an architect must know exactly which parts of the software will be affected. Also important is the cost of implementing the change. Architecture impact analysis is the process of calculating the consequences of an architecture change before applying it to the software. If the architect can track the impact of a change, then it is also possible to automate the actual changing of the software. Automation can help to increase the quality and reduce the cost of implementing the change. Since we do not want to keep modifying the software during each experiment, it is better to use an abstract model of the software.
At Philips we have many years of experience using Relation Partition Algebra [FO94,FKO98,FO99,FK99], which involves a mathematical model based on sets and relations and has proven to be quite adequate for impact analyses of this kind. Using a model of the existing software allows for fast feedback of the impact without the need to modify the software.
The software architecture improvement process that we propose makes a distinction between architecture impact analysis on the one hand and software architecture transformations on the other. Figure 1 shows the software architecture improvement process. Each of the steps in the process (corresponding to the numbers in the figure) will be described successively. An example using the process will be described in Section 3.
The software architecture description is extracted from the software (source code, implementation environment, naming and coding conventions, etcetera) and from the architects by conducting interviews. We first have to define what such a software architecture description is. In general, it describes the relations between so-called design entities, for instance a use relation. Design entities are levels of abstraction that constitute some form of hierarchy or part-of relation, like layers, components, modules, functions. Each software architecture has its own terminology. The result of the extract step is an RPA model.
The RPA model is evaluated. The evaluation gives an image of the software architecture as it is reflected by the RPA model of the software. Metrics corresponding to quality aspects can be calculated. Also, structures can be visualised, for instance using box-arrow diagrams. The architect can now form ideas on how to change the RPA model in order to improve one or more of the quality aspects. Although actions like calculating metrics and building structure diagrams can be automated, the actual decisions must be made in an interactive process with the architect.
Changes are made in the RPA model. Making changes in an abstract model of the software (like RPA) makes it easier to try out ideas, rather than make the changes in the software directly. The results are available more quickly and the software is not corrupted in the process. The architect can try different changes and use backtracking if a change does not lead to the desired improvement of the software architecture. A subsequent evaluate step results in metrics or diagrams of the new model that can be compared with the old model. Several changes can be stacked by repetitively executing a change followed by an evaluate step.
The changes that have been made in the RPA model are now used to submit a recipe. A recipe is an ordered list of transformations that have to be performed on the software. Once we have developed a set of basic transformations for each useful change in the RPA model, the submit step is rather trivial. Finding good basic transformations will be a major topic of future research. The architect can decide to submit several of these recipes, before starting the transform step. However, eventually the recipes must be executed in the order of their creation.
A recipe is used to transform the software. The basic transformations in the recipe are executed in the order of their occurrence. In the implementation, each of these basic transformations can be subdivided into several language-dependent transformations. Automating the transform step of the software architecture improvement process eliminates errors otherwise caused by humans and is much faster.
Once the transform step has been completed for all recipes, the software again reflects the RPA model in such a way as if the RPA model had been extracted from the changed software. The process for software architecture improvement can start again, but the extract step can now be skipped, on the assumption that the tool-chain is error-free. Note that by logging the transformations made in the software, the architect can present the changes to the software crew responsible for maintenance.
The system consists of for instance 1518 units containing software, which are written in different programming languages, to name a few: Fortran, Pascal, PL/M, Chill, SDL, SQL, Prom, several assemblers, Make, RCS and Script. Units use each other by for instance calling a function. An import statement reflects a use relation between units, for instance in the programming language C [KR88] unit7.c can contain a statement
#include"unit3.h".
This means that unit7 uses unit3. (In C a unit consists of a header file, containing function declarations, and a body file, containing function definitions.) The system decomposition is expressed in a part-of relation, for instance the pair <unit7, mod3> is a member of that relation, which means that unit7 is contained in (part of) mod3.
Idea 1:
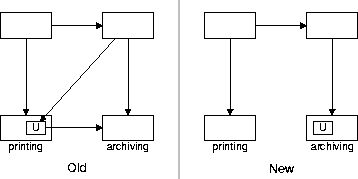
A unit U, containing archiving-related functionality, is located in the printing module and the architect considers moving unit U to the archiving module. To simulate the consequences of this change the architect modifies the RPA model by updating the part-of relation: <U, printing> is replaced by <U, archiving>. In Figure 3 we see on the left the original use relation on module level and on the right we see the new (simulated) view of the system.
After the evaluation of the result, the architect decides to transform his or her idea into a recipe for changing the software. To explain the required modification in the software we first have to discuss how the design entities map onto the elements of the software archive, and explain the build process.
Figure 4 shows a UML class diagram of the relationships of the build description. A version of the software consists of a number of directories in which files reside. Furthermore, a build description belongs to a version, which describes how objects, executables and libraries are created from the software files.
We recall that in the programming language C a unit consists of a header file and a body file. A module is not explicitly available in the archive, but a filename prefix refers to the module name. A subsystem is reflected by a directory and a system maps onto a version. To move unit U from the printing module to the archiving module, we have the following recipe with changes.
Recipe 1:
Idea 2:
In legacy systems, functions may be organised in an arbitrary unit. During construction, a developer is sometimes pressured by time constraints to put a specific function in one unit while semantically it would fit better in another unit. The architect decides to move the function to the correct unit, say function F in unit U to unit X. The detailed recipe for applying this idea to the software depends heavily on for instance the implementation languages. Let us again take the programming language C as an example, then more specifically the recipe contains the following entries.
Recipe 2:
Idea 3:
Several units in the software contain identical functions or so-called function clones. The architect considers removing all but one, and changing the use relation of the units accordingly. The architect uses metrics for cohesion and coupling to determine which of the function clones should remain in the software. Once he or she has determined which function is the best choice (by trying one and using backtracking before trying the next), the following recipe can be executed.
Recipe 3:
In the case of embedded systems we should also consider the target system files (executables, dynamic libraries, scripts). These files are generated during construction and copied to the appropriate location on the target (for instance an EPROM). In a first experiment we decided to keep the target executables the same, i.e. not to change the communication protocols between the executables (which may occur if the architect moves a function from one target to another). In a next experiment, it is possible to also model the execution view of the systems, including the communication, after which the impact of such changes can also be viewed.
In this example we have given three ideas that are of interest to an architect after inspecting the views of the model (like the one presented in Figure 3). One can also consider more automation by introducing algorithms that try several changes using architectural metrics. Architectural metrics also abstract from the details of the system and can indicate some quality aspect of the system at some level of abstraction.
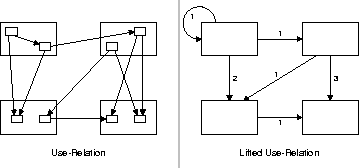
Scripts can be used to extract information from the software often in combination with commercial tools, like QAC [Pro96], Sniff [Tak95] and the Microsoft BSC kit. The type of information extracted is for instance the use relation between functions, otherwise known as the call-graph. The part-of relation for each level of abstraction (Figure 2) can also be extracted. Following the example, the part-of relation between units and modules can be extracted by scanning the filenames of the units for their prefix. Simpler is the part-of relation between modules and subsystems, which relates to files in directories. Note that the same module prefix may have been used in different directories, which in the example is considered an architecture violation that needs to be corrected in a first transformation.
Using RPA expressions, it is possible to add high-level information to the RPA model. For instance, the use relation between units can be calculated by lifting the use relation between functions using the part-of relation between functions and units. RPA has a rich set of operators to calculate the high-level information [FO94,FKO98,FO99,FK99].
It is also possible to add accounting information by using multi-relations [FK99], so that the architect knows how many static function calls exist from one unit to another. Figure 5 shows an example. The left-hand side shows a use relation of units. The right-hand side shows the lifted use relation (module level) with accounting information.
One way of evaluating the recovered architecture is using architectural metrics for the different quality aspects. Metrics are defined using an RPA expression, which can be executed on the RPA model. An example of a metric is the cohesion of a unit, which can be expressed as the quotient of the number of internal static function calls and the number of all possible internal static function calls. Some other examples of metrics are listed below.
The process for software architecture improvement, supported by the proper tooling, gives us an appropriate framework for investigating the impact of changes on an architectural level, as well as a basis for defining new and better metrics for the different quality aspects.
A recipe is a generic description of a so-called architecture transformation. An architecture transformation is a transformation in the software, which has an impact on the architectural model of the system.
An interesting property of architecture transformations is that they can be combined, so larger architecture transformations can be constructed as a sequence of smaller architecture transformations (see the example below).
Our goal is to identify a set of useful architecture transformations. This set will include basic architecture transformations (i.e. architecture transformations that are not described as a sequence of smaller architecture transformations) and composite architecture transformations. Composite transformations consist of a number of basic transformations, but have a right of existence of their own (mostly because they are frequently used). We expect this set of useful architecture transformations to grow in time as we gain more insight into the kind of transformations needed. The basic and composite architecture transformations can be seen as building blocks, from which recipes can be constructed.
There are several advantages of constructing recipes as sequences of architecture transformations over constructing them by hand.
We will now give some examples of possible architecture transformations, both basic and composite, based on the example given in Section 3.
CreateUnit transformation
This basic transformation creates the files for a new and empty unit U. Since the unit is not yet used anywhere, creating it does not have an impact on the build description. In the programming language C, a new body file U.c and header file U.h are created.
DeleteUnit transformation
This basic transformation deletes the files of a unit U given the precondition that the functions in unit U are no longer being used. The build description need not be altered. For the programming language C, the body file U.c and the header file U.h are deleted.
RenameUnit transformation
This basic transformation renames the files of a unit U to a unit V given the precondition that unit V does not yet exist. If unit V does exist, it will be overwritten. Every unit X that uses functions of unit U needs to import unit V instead. In the programming language C, the #include"U.h" is replaced by #include"V.h" in the files of unit X. In the build description, every occurrence of unit U is replaced by unit V.
IsolateFunction transformation
This basic transformation isolates one function F from unit U and relocates it to an existing empty unit V. Every unit X that uses function F needs to import unit V. If unit X does not use any other functions of unit U, the import of unit U can be removed. In the programming language C, the statement #include"V.h" is added to the files of unit X. In the build description, a dependency with unit V is added to unit X.
CombineUnits transformation
This basic transformation combines two units U and V into an existing empty unit W (not equal to U and V ). Every unit X that uses functions from either unit U or V needs to replace the imports with an import of unit W. In the programming language C, the statements #include"U.h" and #include"V.h" are removed from the files of unit X, and a statement #include"W.h" is added. In the build description, every occurrence of unit U and unit V is replaced by unit W.
MoveFunction transformation
This composite transformation moves a function F from unit U to unit V. It can be constructed using the previously defined basic transformations.
Once the ideas have been evaluated and turned into recipes, they can be expressed in architecture transformations as we have seen above. So in principle it is now clear what has to be done in the software. Implementing the transformations is another issue. In order to make automatic changes in the complete software, we implement a software renovation factory. This is an architecture that enables rapid implementation of tools that are typical of code changes. The construction of such factories is beyond the scope of this paper. The interested reader is referred to [BKV96,KV98,BKV98,DKV99,SV99b,SV99a,BD99].
The systems we are dealing with are mixed-language applications. We have to construct a reengineering grammar that understands all applied languages. [SV99a] describes a process and tools generating a reengineering grammar from the source code of compilers. In that paper, 20 sublanguages play a role. When the grammar has been defined, we can generate software that we call a software renovation factory; see [SV99b] for an overview and [BD99] for applications. Setting up such a factory takes time for systems containing dozens of different languages. The individual grammars of the compilers and scripting facilities need to be reverse engineered. The actual generation of the software factories is automatic.
To be able to carry out basic architecture transformations we can annotate some of the software with so-called scaffolding information ([SV99c]). For example, when a function is moved to another file, we can annotate all calls to this function in the source files so that we know in a later stage that we can turn those calls into other calls. It will be clear that the architecture transformations are implemented as complete assembly lines containing many small steps.
To give an example of architecture transformations using scaffolding, when we generate a software renovation factory from a modular grammar, the entire system consists of grammar files, and the transformation is called Gen-Factory. The implementation parses the entire grammar system using scaffolding and the transformation is effected throughout the entire system in about 200 different steps. Similar principles apply to the architecture transformations for systems other than those consisting of grammar files.
The combination of architecture analysis tools and tools that work on the code level is an issue that gained attention at SEI under the name of CORUM [WOL+98,KWC98]. This effort aims at the interoperation of tools by a common format. Our approach differs from theirs in that we do not focus on interoperability, like sharing a parser both for architecture impact analysis and for code transformations. Instead of reusing parser output, we focus on reusing the source code of the parser, so that we can change the parser into a parser appropriate for reengineering [SV99a].
Our approach is more in line with the COSMOS approach for solving the Y2K problem. After analysis, COSMOS returns a prescription of what needs to be done to the code. This prescription can be carried out by hand, or in some cases it can be executed automatically. A difference is that we focus on the transformation's impact on the architecture, which is mostly not the case with Y2K repair engines.
In the impact phase (phase one) we adapt our RPA model in order to evaluate the effect of modifications of the architecture beforehand. This is comparable to the Software Architecture Analysis Method or SAAM [BCK98, Ch. 9]. The mathematical foundations of RPA [FO94,FKO98,FO99,FK99] are similar to the mathematical foundations of [Hol98].
We have shown that the process for software architecture improvement is flexible in experimenting with new metrics and changes, in order to find those best suited for the systems we investigate. By forming ideas and trying them out in the model we can perform an early impact analysis. The changes made in the model are submitted as recipes containing high-level architecture transformations, which themselves consist of basic and composite transformations.
The process for software architecture improvement separates architecture impact analysis from architecture transformations, which presents the following advantages from making changes in the software directly.
The feasibility of the approach has already been proven in [Bro99] for clone elimination. In our future work we intend to test and implement this process for software architecture improvement. Our work will comprise the following steps.